Die Hotlinkfarmen boomen
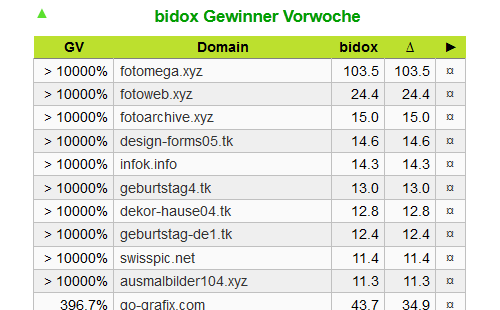
bidox – Gewinner der Woche 40/2015
Vorbemerkung: Es geht hier um die Google-Bildersuche bei google.de. Allerdings ist die englische Bildersuche bei google.com auch betroffen.
Das sind die Gewinner der letzten Woche im Bilder-Domain-Index (Bidox). Alle Domains habe ihren bidox-Wert aus den Nichts erreicht, wobei in der Liste nur Seiten angezeigt werden, die mindestens einen Wert von 10 erreicht haben. Für fotomega.xyz ging es sogar von 0 auf über 100, aber diese Website ist bereits Geschichte.
So einen steilen Aufstieg in der Google-Bildersuche erreicht man in der Regel nur mit vielen Hotlinks auf topplatzierte Bilder. Diese Hotlink-Farmen sind nicht neu, sie haben nun aber das System perfektioniert.
Nur die Top-Bilder zählen
Für die Hotlink-Spammer sind natürlich nur die Top-Bilder lukrativ, weil man mit diesen nich nur in der Bildersuche selbst, sondern auch in der Bilderbox der organischen Suche oder im Knowledge-Graph mitmischen kann. So sieht dann das Ergbnis aus:
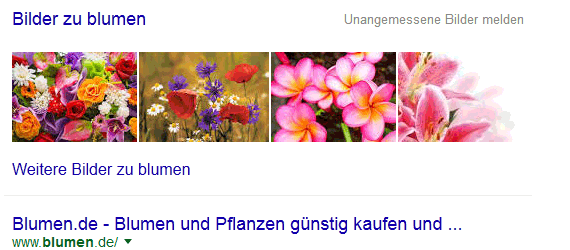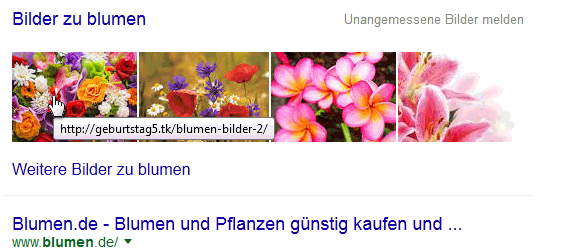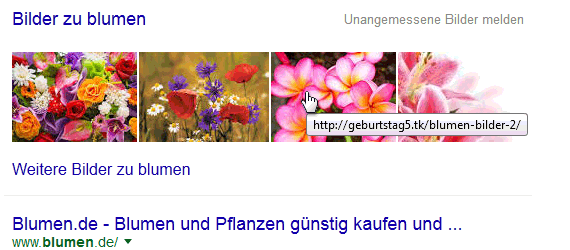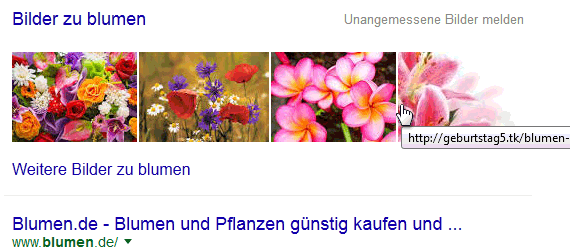
Google-Bilderbox: Blumen
Im ersten Beispiel „Blumen“ zeigen alle vier Bilder der Bilder-Box auf die Hotlinkfarm geburtstag5.tk.
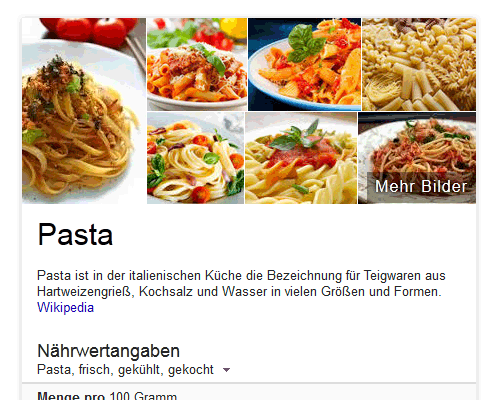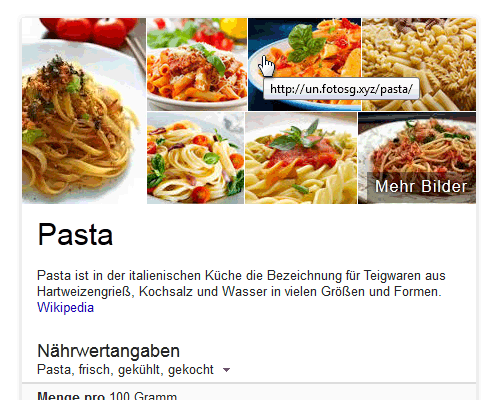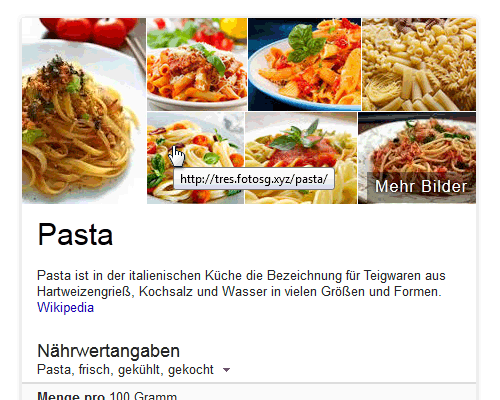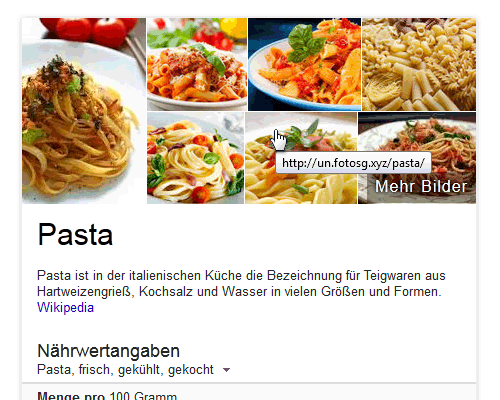
Google-Knowledge-Graph: Pasta
Beim Knowledge-Graph für „Pasta“ wurden zwar nicht alle Bilder von den Hotlinkern gekapert, aber man sieht schon das neue Konzept der wechselnden Sub-Domains. Zwei Bilder zeigen auf un.fotosg.xyz, ein anderes auf tres.fotosg.xyz. Jetzt, wo ich diesen Artikel hier schreibe, werden bereits alle Seiten auf die neue Domain fotoweb.xyz umgeleitet.
Domain wechsle dich
Um gar nicht erst von möglichen Antispam-Maßnahmen behelligt zu werden, wird praktisch täglich die Subdomain und nach ein paar Tagen auch die Hauptdomain gewechselt. Sollte jemand bei Google einen Spam-Report oder gar eine DMCA-Beschwerde einreichen, ist die Hotlink-Farm längst auf eine neue Domain umgezogen und kann ungestört weitermachen, bevor da überhaupt etwas bearbeitet wurde.
Die Seiten laufen, soweit ich das gesehen habe, mit WordPress. Da ist so ein Sub-/Domainwechsel sehr einfach zu bewerkstelligen.

Wordpress-Einstellungen: URL
Nachdem man die neue Domain registriert und auf den Webspace aufgeschaltet hat, muß man nur noch in den Allgemeinen Einstelluneg die gewünschte Domain oder Subdomain bei WordPress-Adresse und Website-Adresse eintragen. Fertig ist die Laube, um alles andere inklusive Weiterleitung der Zugriffe auf die alte Domain zur neuen Domain kümmert sich WordPress.
Geld verdienen leicht gemacht
Die Hotlinkfarmen werden selbstverständlich nicht nur zum Spaß aufgebaut oder um Bilder-Menschen wie mich zu ärgern. Man kann mit den Hotlinks prima Geld über Werbung verdienen.

So sieht eine der .xyz-Seiten aus, wenn man sie besucht. Es gibt ein bißchen schlecht (automatisch) vom Türkischen ins Deutsche übersetzten Text und natürlich die per Hotlink eingebundenen Bilder, teilweise per display:none versteckt.
Dazu kommen für die interne Verlinkung „Related posts“, „Recent Posts“, „Archives“, „Categories“ und „Zufällige Bilder“. Im Archiv kann man übrigens sehen, wann die Hotlink-Farm an den Start gegangen ist. Der erste „Artikel“ ist vom 3. August 2015.
Zum Geldverdienen dürfen auch Werbveblöcke nicht fehlen, davon findet man bescheidene drei auf der Seite.
Ich weiß zwar nicht, wieviel so eine .tk- oder .xyz-Domain in der Türkei kostet, aber selbst wenn die Domain nach wenigen Tagen verbrannt ist, dürfte sie in dieser Zeit locker das Geld plus einen guten Gewinn eingespielt haben.
Ist Google machtlos?
Es ist ja wirklich toll, wie rührig sich Google bemüht, Spam aus den organischen Suchergebnissen fernzuhalten. Da gibt es immer wieder neue Updates mit putzigen Tiernamen und die Spammer bekommen das große Zittern.
Wer sich allerdings auf Bilder-Spam mit Hotlink-Farmen spezialisiert hat, kann sich schon seit Jahren entspannt zurücklehnen. Im Bereich der Bildersuche muß man da nichts befürchten.
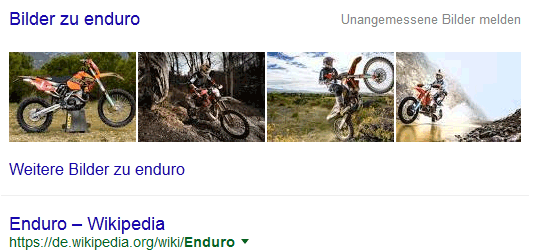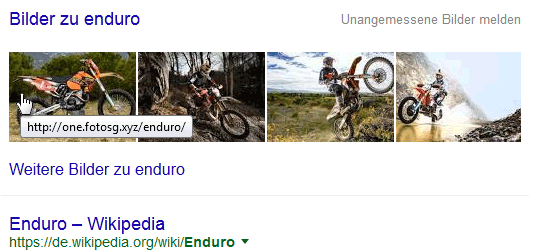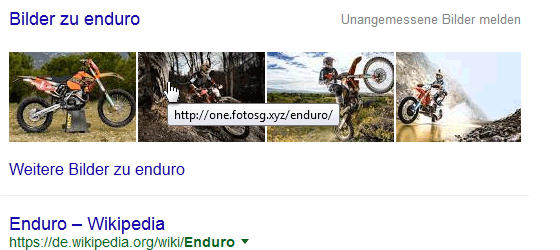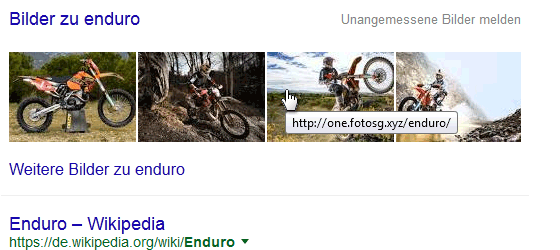
Google-Bilderbox: Enduro
Im Gegenteil, ich habe sogar den Eindruck, daß es seit einiger Zeit viel schneller als früher möglich ist, ein Bild per Hotlink in den Suchergebnissen zu übernehmen. Gerade bei Bildern in der Bilder-Box oder im Knowledge-Graph passiert das fast in Echtzeit.
Dabei wäre die Spamerkennung bei den großen Hotlink-Farmen denkbar einfach. Wenn eine Website in kurzer Zeit Bilder von vielen unterschiedlichen Domains einbindet, dann sollte bei Google eine rote Spam-Warn-Lampe angehen.
Und warum muß ein Bild immer sofort auf eine neue Seite in den Suchergebnissen verweisen, wenn es irgendwo auf einer neuen Seite auftaucht? Stellt eine Seite, nur weil sie neu ist, einen größeren Mehrwert für den Besucher dar?
Ich denke nicht, daß Google bei dem Problem des Bildersuche-Spams machtlos ist, zumal es aus meiner Sicht recht starke Signale für Bilderspam gibt.
Google kümmert sich einfach nicht um die Bildersuche und dreht lieber im 127. Panda-Update an Stellschraube 68, so daß möglicherweise 0,03% weniger Spam bei den organischen Suchergebnissen zu finde ist.

")
")
")