Bilder beim Conversionzauber SEO-Contest

Conversionzauber – Sonnenaufgang
Obwohl bei den meisten SEO-Wettbewerben, wie auch beim Conversionzauber, Bilder nicht gewertet werden, werfe ich gerne einen Blick auf die Rankings in der Bildersuche.
Welche Bilder liegen vorn oder schaffen es überhaupt ins Ranking, was für Bildtypen und Formate sind zu finden und welche Metadaten werden verwendet?
Die Google Universal Search Bilder Box
Fast vom Start weg hat Google in den organischen Suchergebnissen die Bilderbox angezeigt. Die Integration erfolgt in den SERPs an wechselnden Positionen, oft auf der ersten Seite. Ich habe mal meine Ranking-123 Conversionzauber-Daten tageweise nach bester und schlechtester Platzierung subsummiert und in ein kleines Diagramm gepackt:
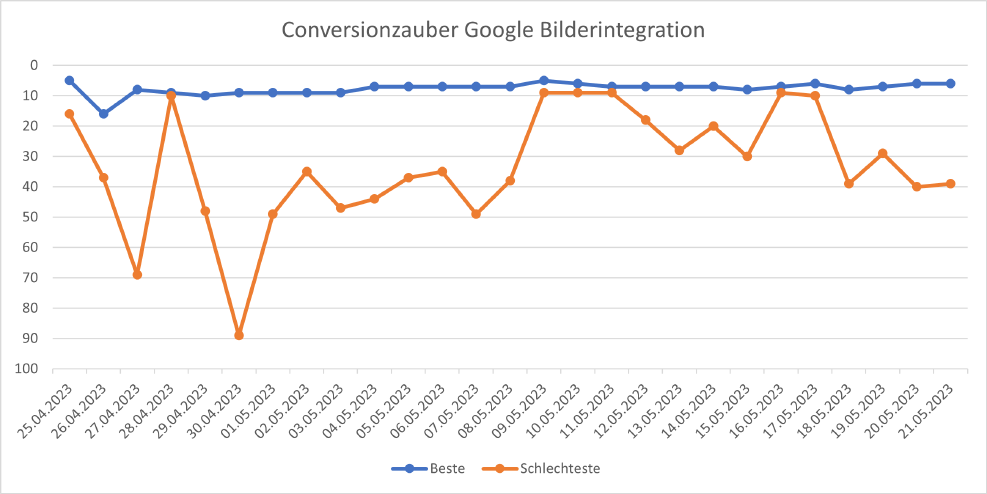
Die bisher höchste Position war Platz 5 am 25.04. und 09.05., stark zurückgefallen war die Bilderbox am 30.04. auf Platz 89. Zeitweilig waren die Bilder auch ganz verschwunden, dann aber nur für ein paar Stunden am Tag.
Welche Bilder sind in der Bilderbox zu finden? Sind es die Bilder von den Seiten aus der Top 10 der organischen Ergebnisse oder ist es die Top-10 der Bildersuche?
Seit einiger Zeit werden die Bilder in einem sogenannten Karussell angezeigt, eine horizontale Liste, die gescrollt werden kann. Enthalten sind hier üblicherweise zehn Bilder, von denen aber nur vier oder fünf direkt sichtbar sind. Aktuell (21.05.2023 18 Uhr) sind das folgende Bilder:
| BB |
OS |
BS |
URL (Bild/Seite) |
| 1 |
19 |
7 |
www.khoa-nguyen.de/wp-content/uploads/2023/04/Conversionzauber.jpg |
| www.khoa-nguyen.de/events/conversionzauber-contest-2023/ |
| 2 |
12 |
– |
www.i-doit.com/hs-fs/hubfs/magier-idee-conversionzauber.png |
| www.i-doit.com/conversionzauber/ |
| 3 |
1 |
2 |
uploads-ssl.webflow.com/64108bd6a813cccdd63606f9/6447a57adbde2bd370becb83_conversionzauber.jpg |
| www.hurra.com/conversionzauber |
| 4 |
79 |
21 |
www.textvorsprung.de/wp-content/uploads/2023/04/conversionzauber_header.png |
| www.textvorsprung.de/conversionzauber/ |
| 5 |
2 |
4 |
media.dm-static.com/image/upload/q_auto:eco,f_auto/content/rootpage-dm-shop-de-de/resource/image/1849324/landscape/400/281/3962d2007d6d4308266ec137df5df2e0/B47A8B8061D82304AE1D15FDEC2CFFBF/teasergruppe-5-bild.png |
| www.dm.de/moduluebersicht/conversionzauber |
| 6 |
38 |
28 |
students-for-students.de/wp-content/uploads/2023/04/Conversionzauber-SEO-Contest-2023.webp |
| students-for-students.de/conversionzauber-10-gruende-warum-er-nicht-immer-funktioniert |
| 7 |
4 |
16 |
camediaonline.com/wp-content/uploads/2023/04/zaubertuer.png.webp |
| camediaonline.com/conversionzauber/ |
| 8 |
9 |
39 |
www.webmen.de/conversionzauber/wp-content/uploads/2023/04/Conversionzauber-leicht-gemacht.jpg |
| www.webmen.de/conversionzauber/ |
| 9 |
3 |
3 |
www.tolingo.com/hubfs/conversionzauber-in-allen-marketingphasen.webp |
| www.tolingo.com/de/conversionzauber |
Zu den Rankings in der Bilderbox (BB) habe ich noch die Positionen der Seite in der organischen Suche (OS) und des Bildes in der Bildersuche (BS) aufgelistet. Gute oder schlechte Platzierungen in der organischen bzw. Bildersuche bedeuten nicht automatisch einen oder keinen Platz in der Bilderbox.
Auf Platz 4 in der Bilderbox steht ein Bild von textvorsprung.de, in den „normalen“ Suchergebnissen ist die Seite aber erst auf Platz 79 zu finden.
In der Universal Search hat es ein Bild von i-doit.com auf Platz 2 geschafft, in der organischen Suche liegt die Seite auf Platz 12. Das Bild ist in der Bildersuche gar nicht zu finden, wohl aber andere Bilder der Website.
Anders gesagt, mit Bildern kann man auch ganz gut vorne mit dabei sein, selbst wenn es in der organischen Suche nicht zu Top-Platzierungen reicht. Nur bei einem SEO-Wettbewerb hat man nichts von guten Bilder-Rankings. :-)
Conversionzauber Bilder in Zahlen
Aus meinen Ranking-123- und Bidox-Daten kann ich auch allerlei andere Zahlen erheben, vergleichen und bewerten. Wie große sind die meisten Bilder und welche Bild-Typen und -Formate werden verwendet?
Ich habe hier jeweils die letzten Bidox-Daten (KW 18/2023) und die Conversionzauber-Daten gegenübergestellt. Im Bidox werden aktuell ca. 1,5 Mio Bilder erfaßt, zum Conversionzauber gibt es zurzeit 720 Bilder.
Bildgrößen
Google bietet in der Bildersuche einen Filter für Bildgrößen an: Groß (large), Mittel (medium) und Icon (icon). Früher gab es auch noch die Größe „Klein“ (small). Hier die Verteilung der Bilder in den Größenklassen:
| Name |
Größe |
Bidox |
Conversionzauber |
Bidox 2017 |
| icon |
bis 256×256 |
1.7% |
7.1% |
9.1% |
| small |
bis 400×300 |
5.3% |
13.4% |
19.3% |
| medium |
von 400×300 bis 1024×768 |
48.4% |
50.5% |
55.9% |
| large |
ab 1024×768 |
46.4% |
36.2% |
24.8% |
Beim Conversionzauber liegt der Schwerpunkt bei den mittelgroßen Bildern, die die mit 50.5% eine knappe, absolute Mehrheit haben. Insgesamt geht der Trend im Bidox aber eher zu großen Bildern, wie auch der Vergleich mit den Daten von 2017 zeigt. Kurz gesagt, die Bilder werden immer größer.
Das größte derzeit im Bidox erfaßte Bild, eine Darstellung des Orionnebels in der Wikipedia, hat übrigens die Abmessungen von 18000 x 18000 Bildpunkten, das entspricht ca. 300 MP bei einer Dateigröße von 37 MB. Das größte, z.Z. rankende Conversionzauberbild hat die bescheidenen Abmessungen von 5471 x 3605 Pixel.
Bildtypen
Der Bildtyp ist das Speicher- und Kompressionsformat eines Bildes, also JPEG, PNG oder WEBP. Auch hier zunächst die Übersicht der Zahlen:
| Typ |
Bidox |
Conversionzauber |
| jpg |
86.957% |
59.880% |
| png |
10.360% |
30.240% |
| webp |
1.709% |
7.335% |
| gif |
0.581% |
0.749% |
| svg |
0.385% |
1.796% |
| bmp |
0.004% |
– |
| tif |
0.003% |
– |
Im Bidox dominieren immer noch die JPG-Bilder und auch beim Conversionzauber machen sie den größten Anteil aus, wenn auch nicht mehr so deutlich. Überraschend hoch ist bei den Zauberbilder der Anteil des PNG-Formats und noch ungewöhnlicher ist der im Vergleich zum Bidox relative hohe Prozentsatz von WEBP-Bildern.
Letzteres hängt aber vermutlich besonders mit dem sehr unterschiedlichen Alter/Größe des Internets und des Conversionzaubers zusammen. Wer neue Bilder erstellt, wie etwa für einen ganz neuen Suchbegriff, wird dann doch das seit vielen Jahren von Google angepriesene WEBP-Format verwenden. In der Masse der schon existierenden Bilder geht das aber statistisch gesehen noch unter. Aber auch ganz allgemein ist hier ein Aufwärtstrend zu erkennen:
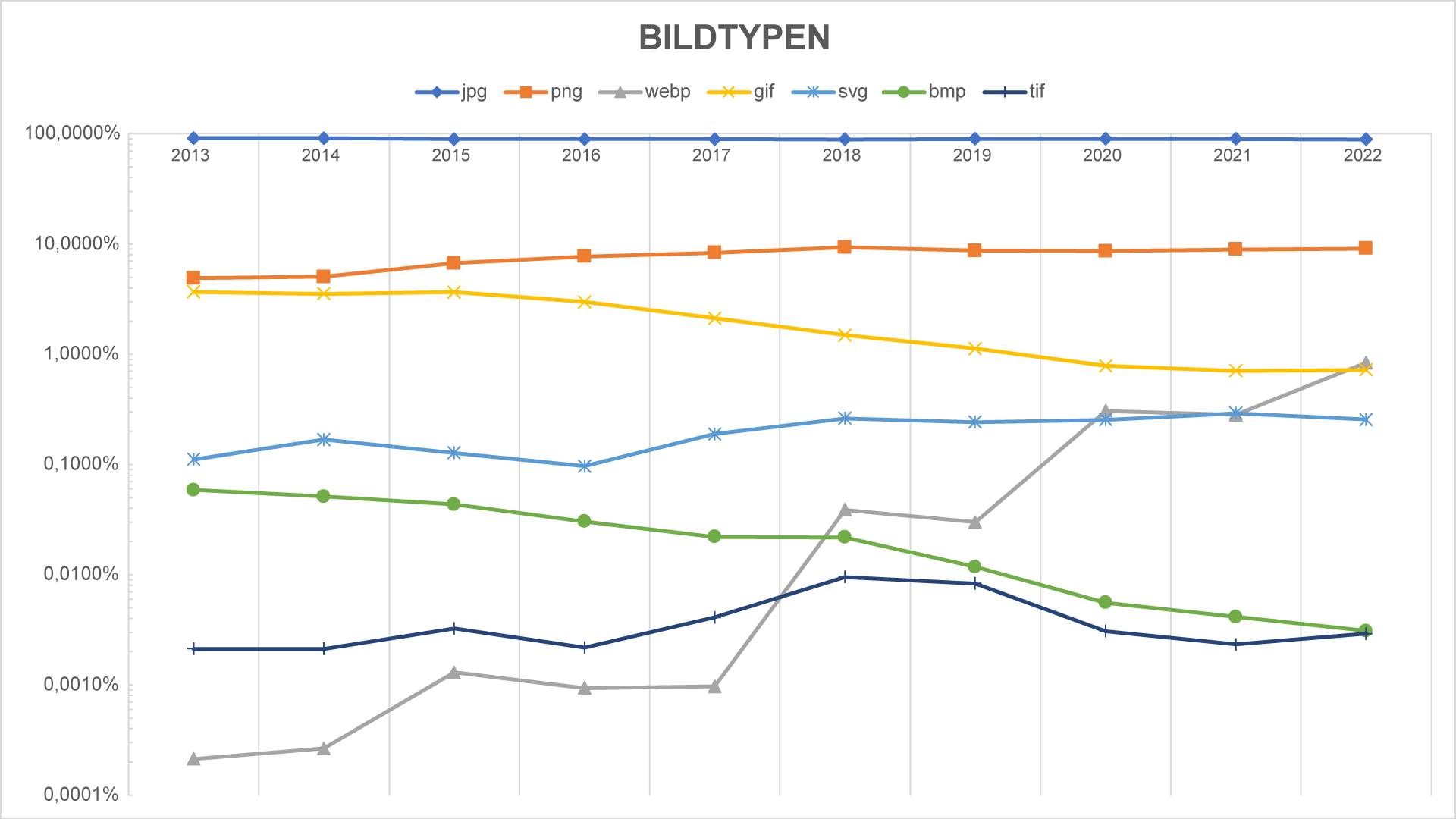
Die Darstellung ist hier logarithmisch, sonst würde man in den unteren Prozentbereichen kaum eine Veränderung erkennen können.
Bildformate
Mit Bildformaten ist hier das Seitenverhältnis der Bilder gemeint, also gängige Werte wie z.B. 16:9 oder 4:3. Hier zunächst die Zahlen:
| Format |
Bidox |
Conversionzauber |
| 1:1 |
28.832% |
44.706% |
| 16:9 |
26.103% |
19.294% |
| 3:2 |
21.013% |
22.353% |
| 4:3 |
13.601% |
8.471% |
| 3:4 |
5.067% |
1.647% |
| 2:3 |
4.462% |
1.647% |
| 9:16 |
0.921% |
1.882% |
Ich habe hier die Seitenverhältnisse für die Statistik nicht ganz exakt genommen, sondern mit einer Toleranz versehen, innerhalb derer ich ein Bild noch zu einem Format zuordne. Wenn das Bild z.B. die Abmessungen 300×297 Pixel hat, ist es für mich, und ich würde auch sagen für einen normalen Betrachter, quadratisch (1:1), auch wenn es rechnerisch nicht stimmt.
Was genau steckt hinter den Formaten bzw. wo kommen sie her und wie sind sie entstanden?
- 16:9 (HD, Full HD, TV-Formate) z.B. 1280×720, 1920×1080
- 1:1 (Instagram, WP Artikel- u. Vorschaubilder)
- 4:3 (klassische TV- und PC-Formate) z.B. VGA IBM PS/2 640×480, SVGA 800×600
- 3:2 (Digitalkamera und analoge Fotoformate) z.B. Kleinbild 24×36 mm, Mittelformat 6×9 cm
Der Trend zum quadratischen Format (1:1) hat sich bereits im Bidox abgezeichnet.
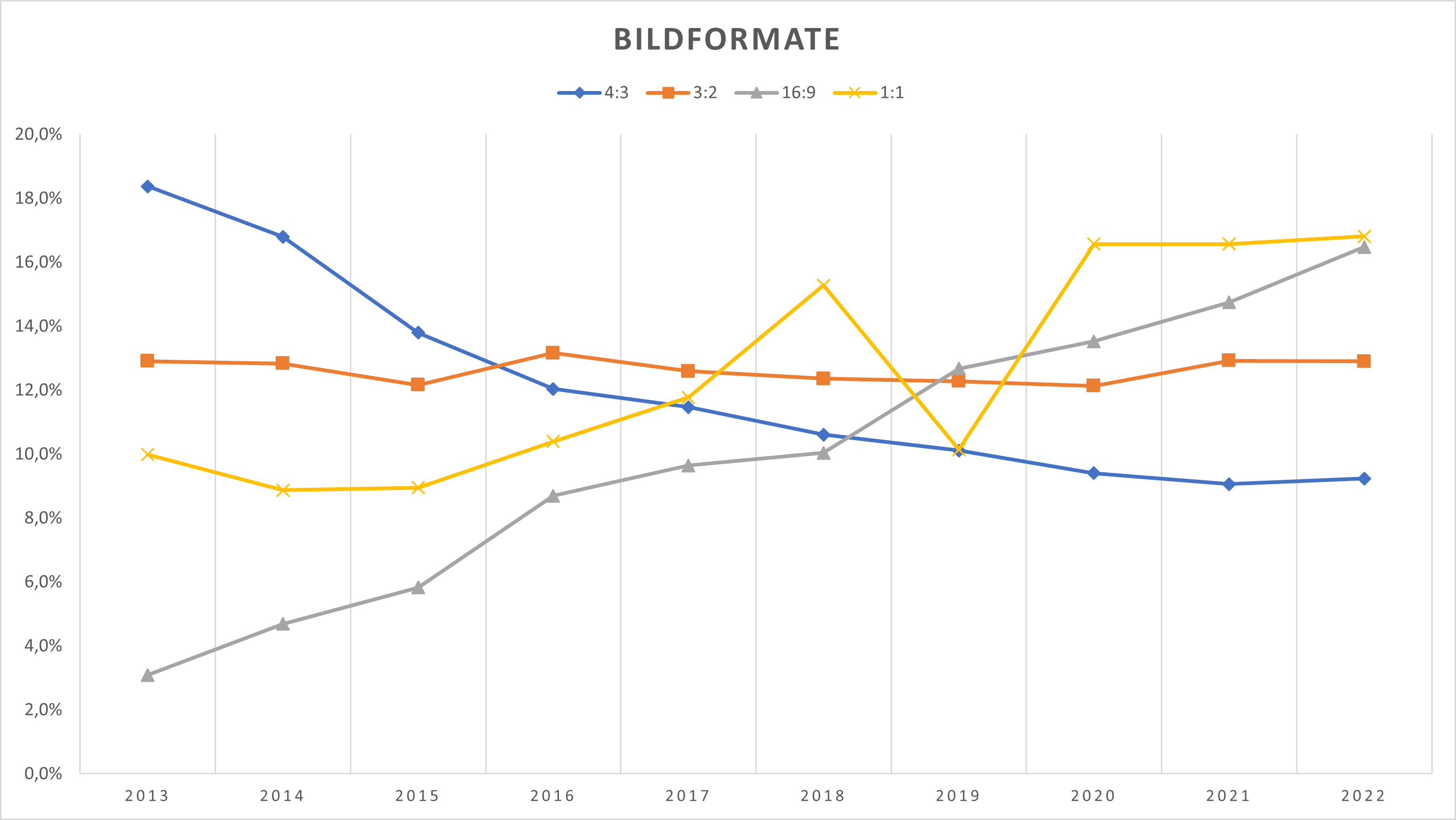
Daß er sich bei den Conversionzauber-Bildern so deutlich zeigt, hätte ich nicht erwartet. Ich habe aber eine Idee, woran das liegen könnte.
Ich gehe davon aus, daß eine gewisse Zahl von Bildern durch eine KI generiert wurden. Ich selbst kenne zwar nur Bing, aber da waren die von mir erstellten Bilder immer quadratisch. Und auch viele KI-Beispielbilder, die ich z.B. auf Facebook gesehen habe, sind quadratisch.
Also scheint die KI sogar einen Einfluß auf die Statistik der verwendeten Bildformate zu haben.
Meine Conversionzauber Bilder
Neben den automatisch generierten Ranking-123-Charts habe ich drei weitere Bilder ins Rennen geschickt.
-

-
Conversionzauber – Sonnenaufgang
-

-
Conversionzauber Kanne
-
-
Conversionzauber Geld
Den zauberhaften Sonnenaufgang habe ich bereits als Headerbild bei Ranking-123 benutzt, zunächst als JPG-, später dann auch als WEBP-Datei mit zusätzlichen Meta-Informationen.
Das zweite Bild ist die asiatische Teekanne, ein Foto, das ich auch bei Adobe-Stock anbiete. Seit ein paar SEO-Wettbewerben schicke ich als Gimmick immer wieder eines meiner Stock-Bilder ins rennen. Die ursprünglich bei noch bei Fotolia eingestellten Bilder kann ich nun bei Adobe relativ leicht bearbeiten, also Titel, Beschreibung und Stichwörter ändern. Das ging früher bei Fotolia nicht so ein fach.
Und noch ein Bild habe ich dazugenommen, weil es beim Conversionzauber wie immer nur ums Geld geht. Das Bild den Euroscheinen und -münzen hatte ich schon länger „auf Halde“ liegen und bsher noch nicht verwendet.
Eher ernüchternd sind die Rankings meiner Bilder in der Google-Bildersuche:
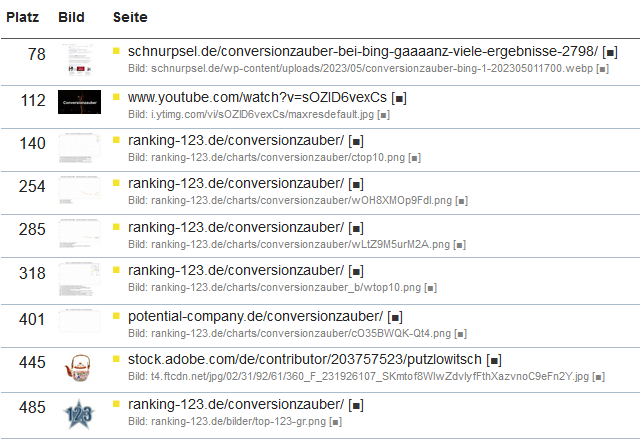
Zumindest in der Top-100 ist der Screenshot zu meinem Artikel zu finden. Alles andere an Bildern ist jenseits der 100 platziert. Ganze fünf Ranking-Charts und das Ranking-123-Logo haben es in die Bildersuche geschafft.
Interessant find ich das Teekannen-Bild bei Adobe-Stock auf Platz 445. Das is nicht etwas das Einzelbild, sondern das Thumbnail aus meinem Anbieter-Profil. Auf der Seite dort ist der Suchbegriff noch nicht einmal direkt sichtbar. Nun ja.
Aber meine „richtigen“ Bilder haben es leider bis jetzt nicht geschafft. Dabei dachte ich, ich kenne mich mit der Bildersuche ein wenig aus…












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}