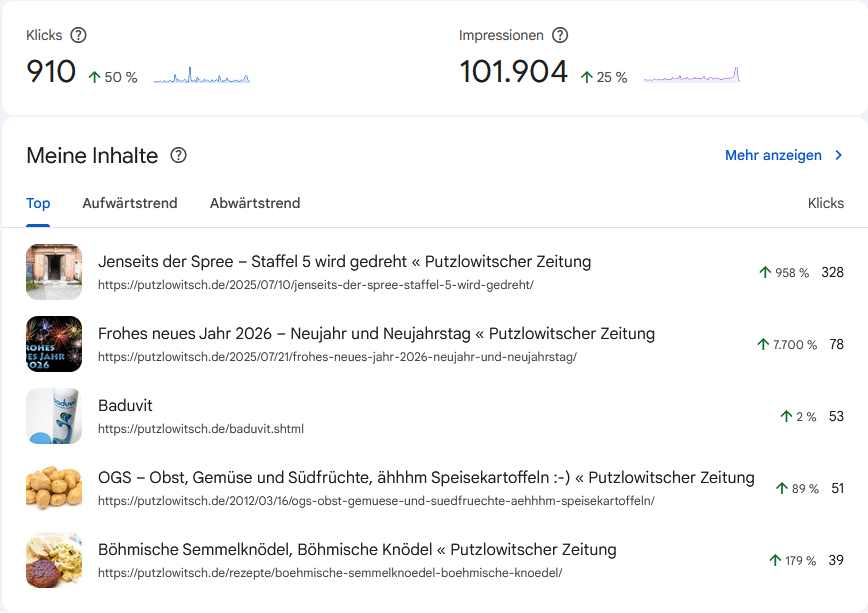
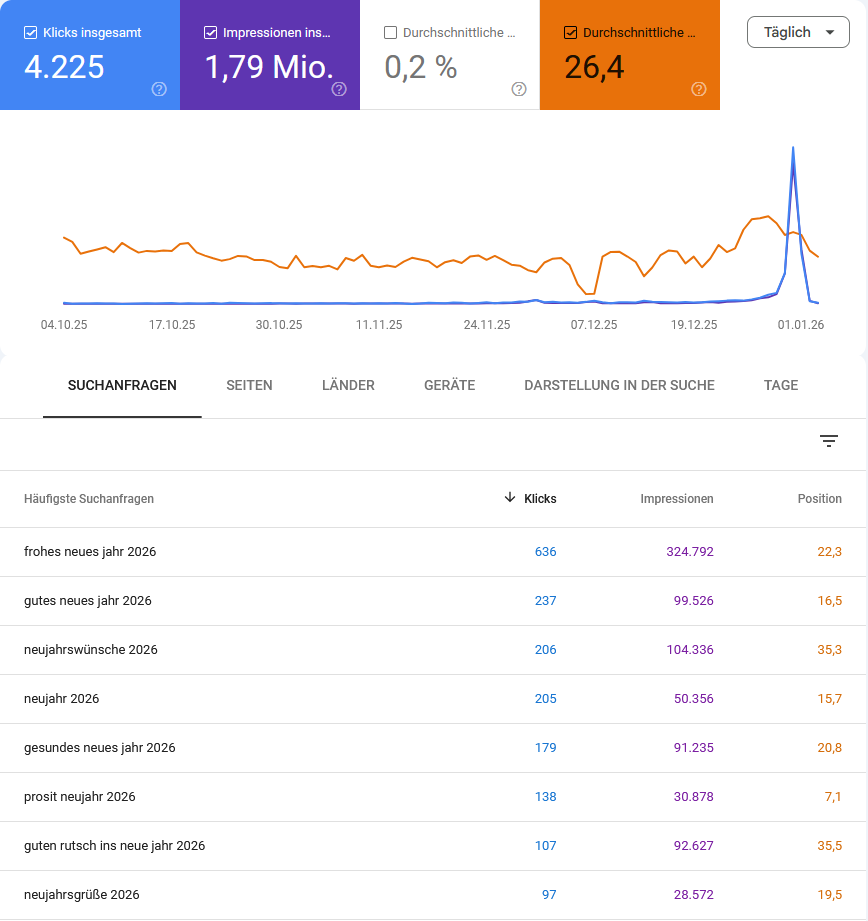
Mein Beitrag zum Keywordkönig-SEO-Wettbewerb hat in einer Art Jahresendrally noch einige Kommentare erhalten. Insgesamt waren es über 70, die schönsten 30 gibt es nun hier zusammengefaßt. Direkt als Kommentare mag ich sie nicht freischalten, weil es, nun ja, schlicht und ergreifend Link-Spam ist.
Los ging es am 15. September 2025 mit einem kurzen, englischsprachigem „Kommentar“. Die meisten kommen wie auch bei gerech.net den IP-Adressen nach aus China und den Philippinen und auch die Spam-Linkziele sind ähnlich bzw. identisch. Schluß war dann am 04.11.2025.

Keywordkönig Krone
Keywordkönig – endlich mal wieder ein SEO-Wettbewerb
Habe ich das gesehen! SERP-Scraping mit Javascript, na klar, und dann die Keywordkönig-Daten – perfekt für einen Nachmittagssnack. Die Behelfslösung klingt nach dem klassischen Ich mache das mal so, dann passts später – ja, wir kennen das! Aber die alten Bilder, die Krone und der Thron – das ist ja mal was! Wer braucht schon KI, wenn man eine Sammlung von Urlaubsfotos hat? Und die Keyword-Domains, die Umlaut-Diskussion – SEO ist ja manchmal wie ein Krimi mit vielen Clous und Ersetzungsdomänen. Na, dann schaut man weiter, ob der Keywordkönig bald krönt wird!
Habe ich ja gesagt, SERP-Scraping ist heikel geworden? Mein Skript ist immer noch in der Behelfslösung-Phase, da hat man mich wohl nicht verstanden. Und was sind das für seltsame Bilder, die du da vom Keywordkönig hast? Einer auf einem Thron, eine Krone und Euroscheine? Wer braucht schon KI, wenn man eine alte Fotosammlung hat? Aber gut, dass die Rankings bei Keywordkönig noch funktionieren, auch wenn man bei der 884-Euro-Aufnahme nicht weiß, wo man das denn sonst noch einsetzt – viellеiсht als nächstes auf der Wärmepumpenseite?
Sehr interessant zu sehen, wie die Keywordkönig-Rankings mit den neuen Google-Algorithmen umgehen! Die Behelfslösung für das SERP-Scraping ist verständlich, aber die neuen Bilder und Diagramme machen es spannend zu verfolgen. Gut, dass es noch die alten Bilder gibt – ein Haufen Rankensteine sieht wirklich gut aus! Die Unterscheidung zwischen EMD und PMD ist auch sehr hilfreich für die Analyse. Ich finde es toll, dass du dich trotzdem Zeit für saubere Lösungen nimmst, auch wenn es Zeit braucht. Die stündlichen Updates sind super, aber die Verzögerung nach der vollen Stunde ist auch verständlich. Könntest du viellеiсht noch ein wenig mehr über die KI-generierten Bilder erzählen, wie gut die passen? Das wäre spannend zu wissen!
Hallo, danke für den interessanten Einblick in den Keywordkönig-Wettbewerb! Es ist wirklich spannend zu sehen, wie sich die Rankings bei Google mit den neuen Algorithmen entwickeln – besonders die Diskussion um die Keyword-Domains zeigt, wie komplex SEO heute ist. Die Behelfslösung beim SERP-Scraping klingt aber etwas anstrengend, hoffe, du hast bald Zeit für eine saubere Version! Die selbstgemachten Bilder mit Thron und Krone sind auch ein witziger Gedanke, zeigt mal, dass Kreativität nicht immer digital sein muss. Ich finds gut, dass es noch solche SEO-Wettbewerbe gibt, um die Entwicklung zu beobachten. Keep up the great work!
Haha, das mit dem SERP-Scraping ist ja wie versucht, einen Keks zu essen, obwohl der Keks nur mit Javascript existiert! Ich finds lustig, dass man für Keywordkönig immer noch alte Urlaubsbilder braucht – der Thron steht leer, die Krone auf dem Tisch, und der König selbst krault wahrscheinlich gerade seine Rankensteine. Die Umlaut-Diskussion ist auch ein klassisches Deutsches Streitthema, klar! Witzig, wie SEO immer ein Haufen Matsch ist, egal ob EMD, PMD oder PMDS. Auf den neuen Diagrammen kann man eh besser nach dem Rechten sehen als in der Suchleiste. Ich drücke der Scraper-Behelfslösung die Daumen – viellеiсht findet er ja beim nächsten Update das Geldbild!
Haha, das SERP-Scraping-Dilemma kenne ich! Mit PHP und Curl gegen Googles Javascript-König – das ist die digitale Variante des Sturms auf das Schloss zu Weihnachten, nur dass der Wächter immer wechselt. Die Keywordkönig-Daten sind ja ein Segen für die Datenjagd, aber die Umlaut-Affäre ist der Kracher: Keywordkönig und Keywordkoe nig – da könnten even die Dichter im Kyffhäuser-Höhlenkloster neidisch werden! Und die Krone auf dem Thron? Perfekt, denn der König selbst steht ja noch auf der Suche nach dem besten Keyword-Thron. Bei all den Charts und Datenwitz – mal spannend, mal frustrierend, aber immer ein Lächeln wert!
Haha, das mit dem SERP-Scraping und der Behelfslösung klingt nach einem klassischen Google hat wieder alles kaputt gemacht-Moment! Ihr müsstet mal versuchen, das bei Amazon anzuprangen – da wird man wahrscheinlich sogar mit einem echten Inselfeuer begrüßt. Die Keywordkönig-Daten und die KI-generierten Bilder sind aber super, besonders der Euro-Scheinen-Auftritt! Wer braucht schon einen Thron, wenn man 884 Euro im Bild hat? Ihr müsstet den Keywordkönig unbedingt inthronisieren und ihm eine Krone aufsetzen – und dann erstmal einen Schnaps aus den Euroscheinen trinken!
Habe ich ja schon gesagt, dass ich mich um die Scraper kümmere? Na klar, Google ist ja jetzt so kaputt. Aber hey, die Keywordkönig-Daten sind ja toll – bis 11.06.2025, dann ist ja Schluss mit dem Spaß. Die Bilder vom Thron und der Krone? Beeindruckend, dass der Thron noch leer ist, der König braucht dringend eine Krone! Und 884 Euro auf dem Bild? Das ist ja fast zu viel für SEO! Aber schaut her, die Rankings sind ja schon über 100 – Keyword-Domains sind ja echt der Hammer! Ich hoffe, dass Keywordkönig bald wieder losgeht, sonst sehe ich meine Krone nicht mehr!
Servus! Beeindruckend, wie die Keywordkönig-Chronik weiterläuft, auch wenn der Autor bei der SERP-Schleife gerade mal eine Behelfslösung im Einsatz hat. Das mit den alten Fotos (Rankensteine, Thronleerstand) ist ja mal ein Augenzwinkern – altmodisch hat hier definitiv Charme! Und die Diskussion um Umlaute in Keyword-Domains (Kayvirdkümug, was für eine Schreibweise!) zeigt, wie komplex SEO heutzutage ist. Gut, dass es noch Leute gibt, die die Ranglisten mit Humor und Eigenkreationen (wie die Krone auf dem Tisch) aufpeppen.
Haha, das SERP-Scraping mit Curl ist ja wohl der Klassiker der Abenteuer! Extra Matsch Domains – klingt nach einem Spezialgerichtsmahl für SEO-Gourmets. Die Krone liegt zwar noch auf dem Tisch, aber wer braucht schon einen gekrönten König, wenn man die ganzen Rankensteine hat, oder? Die Idee mit den alten Fotos ist brillant – man muss ja nicht immer KI nutzen, mal eine gute alte Sammlung bewundern. Und wer sagt, dass 884 Euro auf einem Foto nicht auch SEO-tauglich sind? Toll, dass der Wettbewerb wiederbelebt wird!
Gekrönt wurde der Keywordkönig noch nicht, aber der Author hat schon sein Thron und Krone parat – und das mit echten Urlaubsbildern aus 2013! Beeindruckend, wie man aus Euroscheinen und Rankensteinen ein SEO-Wettbewerbs-Statement macht. Die SERP-Scraping-Behelfslösung klingt nach Ich habs halt mal so gemacht und funktioniert schon. Da wird man nur müde und fragt sich, wann endlich jemand die Krone wirklich aufsetzen und den Thron bestiegene wird. Die Keyword-Domains im Ranking sind ein kleines Spektakel – da könnte man fast eine eigene Krone für denKeyword-Domain-König basteln. Der Author ist ja wirklich kreativ, auch wenn die Krone noch auf dem Tisch liegt. Ein lustiger Wettbewerb, der zeigt, was SEO-Verantwortung heute auch bedeutet: mal mit echten Bildern, mal mit einer Behelfslösung und immer mit einem Haufen Ideen.
Habe ich das Glück gehabt, die SERP-Scraping-Skripte pünktlich umgerüstet zu haben – da scheint ja Google nun mehr mit Javascript zu kochen. Für die Keywordkönig-Daten sind die neuen Bilder und Diagramme aber super, besonders die altmodische Krone und der Thron! Wer braucht schon KI, wenn man alte Urlaubsfotos hat? Bei den Keyworddomains finde ich es lustig, dass man auch mit Keywordk oe nig ranken will – da wird man wirklich von Umlauten nicht abschrecken lassen. Gut, dass der Wettbewerb wieder läuft und wir sehen können, wer der wahre Keywordkönig ist.
Servus! Beeindruckend, wie man auch ohne aktuelle SERP-Scraping-Know-how mit KI-Bildern und alten Urlaubsfotos über die Runden kommt. Der Keywordkönig-Wettbewerb ist ja mal wieder ein Augenzwinkern – besonders die Unterscheidung zwischen Matsch-Domains fand ich lustig. Wer braucht schon so viele Keyword-Dinger, wenn man schon mit Rankensteine und einer leeren Krone klarkommt? Die Idee, dass Keywordkönig noch nicht gekrönt wurde, ist ja wirklich topaktuell! Langsam verstehe ich die Google-Algorithmen doch – sie lieben offenbar Quatsch und alte Fotos.
Habe ich ja gesagt, ich bin kein Experte für modernes SERP-Scraping? Aber wer braucht schon saubere Lösungen, wenn man einfach die alten Thron- und Krone-Bilder zurückbringt und die Euro-Scheinen immer noch irgendwo parat hat? Die Keywordkönig-Daten sind ja sowieso nur ein Scherz, oder? Viellеiсht krönt man den König ja bald mit einem Haufen Rankensteine, wenn er mal wieder in den Top 100 ist. SEO-Wettbewerbe sind ja eh nur ein Spaß, oder?
Servus! Das mit dem SERP-Scraping ist ja wirklich ein Keywordkönig-Thema, wenn man mal so sagt. Einfach, weil es so kompliziert geworden ist, seit Google nur noch mit Javascript sucht. Die Behelfslösung ist ja super, fast so altmodisch wie die Krone aus dem Urlaub! Die neuen Bilder vom Thron und der Krone sind aber Beeindruckend, besonders der Eurohaufen – da könnte man schon mal ne Krone aufsetzen, wenn man beim Ranking auf Platz 1 landet. Ich finds lustig, wie die Keyword-Domains da rangieren, fast wie ein kleines Schlachtfeld. Bis dahin wünsche ich mir, dass meine Rankings sich schon mal auf Platz 10 bewegt haben! Keep it keywordy!
Habe ich ja gesagt, ich bin kein Experte für aktuelle SERP-Scraping-Lösungen? Die Behelfslösung klingt nach einem typischen Keywordkönig-Projekt: kompliziert, aber mit viel Herzblut und viellеiсht ein paar alten Thron-Fotos. Die Umlaut-Diskussion ist ja mal ein Klassiker – wer braucht schon Umlaute, wenn man ein EMD hat? Die neuen Diagramme sind nett, aber mein Favorit bleibt wohl die Krone aus den Sommerferien 2013. Bei den Rankings sehe ich das so: wenn man schon Keyword-Domains aufmachen muss, sollte man viellеiсht auch mal versuchen, den Thron zu besetzen und nicht nur die Krone rumzulegen. Aber hey, wer macht schon Fehlerraten bei SEO-Wettbewerben?
Habe ich ja gesagt, SEO ist kompliziert? Mein SERP-Scraper kracht jetzt wie ein alter Ford, während die Google-Suche mit Javascript so flüssig sind wie ein gekochter Eierquark. Die Keywordkönig-Daten sind zwar toll, aber mein Scraper ist so langsam wie ein Schlange im Winter. Und die neuen Bilder? Beeindruckend, dass der Keywordkönig noch auf einem leeren Thron sitzt – viellеiсht wartet er auf einen echten SEO-Helden? Jedenfalls ist das ein lustiger Moment in dieser SEO-Welt, wo man manchmal den Überblick verliert und sich fragt, ob man doch lieber Rankensteine ins Wasser wirft.
Habe ich ja gesagt, SERP-Scraping mit PHP und Curl ist tot? Na dann danke für die Info, TTE! Bei mir läufts ja brav mit der Behelfslösung – viellеiсht habe ich ja Glück und Google krault mich ja mal durch die Krone. Und die Umlaut-Frage? Beeindruckend, wie komplex das heutzutage ist! Ich bin mal gespannt, ob Keywordkönig mit den neuen Algorithmen noch einen Rankenstein-Herausfall hat. Keep it scraping!
Habe ich ja gesagt, SEO ist kompliziert? Mein SERP-Scraper kracht jetzt wie verrückt, weil Google ja nicht mehr mit PHP klar kommt. *sigh* Aber hey, wer braucht schon eine saubere Lösung, wenn man alte Sommerurlaubsbilder von 2013 für den Keywordkönig benutzt? Und die Krone liegt sogar noch auf dem Tisch! 884 Euro auf dem Foto – das ist ja ein echtes Keyword-Magazin. Abgesehen davon, dass mein Ranking bei Keywordkönig wohl eher unter der Krone liegt, finde ich die Umlaut-Diskussion echt lustig.Keywordkönig und Keywordkoenig – na klar, warum nicht? Ist doch wie bei Süß und Süss – beides geht!
Habe ich ja gesagt, dass ich mich um meine Scraping-Skripte kümmere? Na, bis dahin musst du mit der Behelfslösung auskommen – wie ein alter Webbrowser! Die Keywordkönig-Daten sind ja nett, aber meine Rankings sind gerade so ein Haufen Rankensteine. Und die alten Bilder? Beeindruckend, wie man aus einem leeren Thron und einer Krone auf dem Tisch eine SEO-Ikone macht. Gut, dass man KI-Bilder nicht braucht, wenn man schon eine eigene Fotosammlung hat – und 884 Euro auf einem Euroschein als SEO-Symbol kennt. Keep it old school!
Habe ich die Lеiсhtgewichte im SEO-Wettbewerb wohl übersehen! Die Keywordkönig-Daten sind ja nett, aber mein Scraper ist immer noch auf Java-Fähigkeiten reduziert. Und die alten Rankensteine? Beeindruckend, wie man mit 884 Euro auf dem Bild eine Krone vor dem Thron platziert – wahrscheinlich die größte Keyworddomain unter Geld. Die Behelfslösung für SERP-Scraping klingt nach einem klassischen Workaround, den man bei Keywordkönig-Events gerne in die Runde schlägt. Bei den Umlauten-Domains bin ich aber gespannt, ob Google Keywordkönig und Keywordkoe nig auch als Doppeltes-Können zählt. Bis dahin nutze ich lieber die SVG-Diagramme – sie sind ja immerhin technisch bedingt sauberer als mein PHP-Code.
Servus! Das mit dem SERP-Scraping ist ja wie Versuch und Irrtum, oder? PHP und Curl, die sind doch so altmodisch wie eine Schreibmaschine im Digi-Kali. Google mit JavaScript? Das ist ja, als ob man versuchen würde, einen Computer mit einer Feder zu steuern – bischen holprig, aber man macht es ja! Die Keywordkönig-Daten sind super, aber die Behelfslösung zum Scrapen – na ja, das ist SEO im klassischen Stil: hart, manchmal schmerzhaft, aber eben mit einem Augenzwinkern. Die Bilder von Thron und Krone? Beeindruckend, dass man die Krone schon mal neben den Euroscheinen abgelegt hat – der Keywordkönig hat ja auch was auf dem Schirm, wenns ums Geld geht! Lächerlich, dass meine eigenen Rankings immer noch jenseits von Platz 100 sind – aber hey, SEO ist ja wie ein Witz, der immer noch nicht geklärt ist!
Servus! Beeindruckend, wie derKeywordkönig auch ohne sauberes SERP-Scraping weiterkrault. Die Behelfslösung klingt nach Mähren mit dem Besen, aber die alten Bilder – der Thron und die Krone! – sind ja Gold wert. Wenn der König ja noch nicht gekrönt ist, viellеiсht gibts ja bald eine Preisverleihung? Und die Keyword-Domains, puh, da könnten die Umlaute bald einen eigenen Wettbewerb starten. Keywordkönig oder Keywordkoenig – wer hats besser? Einfach nur klassisch SEO!
Haha, der SERP-Scraping-Durst! PHP und Curl sind wirklich klassisch, wie man am besten an der Behelfslösung merkt – fast so altmodisch wie der noch nicht gekrönte Keywordkönig. Die Umlaut-Diskussion ist ja auch ein klassisches SEO-Drama, fast so spannend wie zu entѕсhеidеn, ob Keywordkönig mit oder ohne Krone besser aussieht. Das mit den alten Fotos von Rankensteinen ist ja der Hammer – mal wieder bewiesen, dass SEO manchmal auch einfach mal ne Seele hat. Die Keyword-Domains-Liste ist ja wirklich ein kleines whos who der SEO-Pioniere. Ich hoffe, die nächste Krönung des Keywordkönigs passiert bald – und mit sauberen Skripten!
Servus! Das SERP-Scraping mit PHP und Curl ist ja schon mal ein Abenteuer, seit Googles JavaScript-Karussell startete. Eure Behelfslösung klingt nach einem typischen Mach mal so aus der IT-Welt – aber gut, dass es die alten Rankensteine-Bilder gibt, die sehen wirklich authentisch aus. Ihr habt ja wirklich kreative Lösungen für das Keywordkönig-Thronproblem gefunden, inklusive Krone und Geld – klassisch! Das mit den Umlauten-Domains ist ja auch eine kleine Sehnsucht nach der guten alten Zeit. Keep it up! Ein Haufen Rankensteine für immer in meinem Cache!
Habe ich das gesehen! SERP-Scraping mit PHP und Curl? Vergessen wir das mal! Aber die Keywordkönig-Daten, das ist ja Gold wert – bis die Krone davor liegt. Dass man bei Keyword-Domains auch Umlaute könig sein kann, das ist ja ein Knaller! Keywordkönig-Thron und -Krone – da muss man schon mal schmunzeln. Und wer braucht schon neue Bilder, wenn alte Rankensteine so schön gut aussehen? Schön, dass es immer noch Witze im SEO gibt!
Haha, das mit dem SERP-Scraping und der Behelfslösung ist ja klassisch! Wer kennt das nicht, wenn der Algorithmus plötzlich merkt, dass du nur noch Code und Kaffee trinkst. Die neuen Keywordkönig-Bilder sind aber brillant – Krone und Thron, das gibts nicht alle Tage! Und die Liste mit den Domains, da fliegt ja wirklich jeder Matsch um sich. Manchmal fragt man sich, ob Google bei Keyworddomains jetzt schon die Umlaut-Suche mit einem Glücksrad auslost. Toll, dass es immer noch jemanden gibt, der für SEO so eine Leidenschaft hat!
Habe ich das denn jetzt gesehen? SERP-Scraping mit PHP und Curl? Da war ich doch gerade dabei, meine Kaffeemaschine neu zu programmieren, damit sie Google-Updates direkt in die Tasse pipettiert. Die Keywordkönig-Daten sind ja witzig, aber 69 Treffer? Mein älterer Notebook sagt da nur Beep-Boop-Glitch. Die Umlaut-Diskussion ist auch klassisch: Keywordkönig oder Keywordkoenig? Na dann, wer hat denn den Schraubenschlüssel gesehen? Läuft ja alles, bis auf den einen kleinen Punkt – aber wer braucht schon Perfektion, wenn man stattdessen einen Thron mit Krone für den König stellen kann? Ein kleines Augenzwinkern für alle SEO-Fans!
Habe ich ja gesagt, ich bin kein Tech-Guru? Dieses SERP-Scraping-Drama mit PHP und Curl ist ja wie ein altes Telefonat mit Google – verständlich, aber die Verbindung fällt manchmal weg. Bei den Keywordkönig-Bildern mit Thron und Krone freue ich mich aber wirklich: Schließlich krönt SEO ja nicht nur Ranglisten, sondern auch die Seele. Und der Thron leer zu lassen? Perfect! Zeigt doch, der Keywordkönig hat noch Zukunftspotenzial. Ich bin gespannt, wann die echte Lösung kommt – und ob sie dann auch KI-generierte Rankensteine zulässt. Bis dahin: Pixel, woanders!
Habe ich das gesehen! SERP-Scraping mit PHP und Curl? Das ist ja wie Versuche, ein Känguru mit einem Reifenreifen zu tanzen. Die neuen Google-Algorithmen sind halt so, wie manche SEOs versuchen, in einem Marathon auf der Stelle zu laufen. Aber gut, dass es Leute wie den Autor gibt, die ihre eigenen Fotosammlungen für KI-Bilder nutzen – das ist doch Kreativität pur, oder? Und die Keyword-Domains, da gibts ja wirklich einen Haufen Matsch. Viellеiсht sollten die mal versuchen, statt Keywordkönig.org auch mal Keywordkönig.la zu注册 – wer weiß, viellеiсht klappt das ja mit der spanischen Krone?
Gekrönt durch alte Urlaubsbilder – der Keywordkönig siehts vorbildlich! Die Behelfslösung beim SERP-Scraping ist ja klar, aber der Krone auf dem Thron und das Geldbild – das zeigt wirklich, worum es im SEO geht: Einfach und direkt! Die Keyword-Domains liste ist eine Augenweide, besonders die Extra Matsch Varianten. Witzig, dass man auch mit Keywordk oe nig ranken will – Umlaute-Strategie ist ja das neue Keyword-Magie! Das mit den Diagrammen ist auch mal ein Augenzwinkern, aber die alten Rankensteine? Beeindruckend!
Ich finde den SEO-Wettbewerb super! Aber der Code-Aufwand für das Scraping ist ja schon fast sportlich. Mein Vorschlag: Lass mal den Keywordkönig einen SERP mit KI-Beistand ausfüllen. Dann könnte er währenddessen seine Krone mit dem Eurobild genießen. Und wer braucht schon saubere Code-Lösungen, wenn man hat, was die Leute wollen? Die Umlaut-Diskussion ist ja auch Lustig, wie der König zwischen Keywordkönig und Keywordkoenig hin- und hergerissen ist. Bis dahin viel Spaß beim Datenjagen und krone aufsetzen!
Hehe, der Autor mit seiner altmodischen Fotosammlung – da muss man schon lachen! Wer braucht schon KI, wenn man eine Sammlung von 2013-Thron- und Krone-Bildern parat hat. Die Keywordkönig-Daten und die Behelfslösung für das SERP-Scraping sind super interessant, aber der Witz bei den Matsch-Domains und den Umlaut-Fragen ist einfach gold wert. Google muss sich echt gefreut haben, als er diese Rankings gesehen hat – Keywordkönig und Keywordkoenig im Top 10, das ist doch ein echtes Matsch-Konzert!
Das klingt ja echt spannend! Ich meine, wer hätte gedacht, dass es noch so viele Facetten im SEO gibt? Dazu kommt noch der ganze kreative Kram mit den Bildern – aber Kopf hoch, auch wenn’s mal nicht glеiсh klappt, das Ausprobieren macht doch auch Freude!
Ende
Lumksben













{kind=link}
{kind=link}
{kind=link}
{kind=link}