Wenn ein neuer SEO-Contest startet, fahre ich meist die selbe Strategie, wie schon bei früheren SEO-Wettbewerben. Oder besser gesagt, ich spule eine Art Standardprogramm ab, das von der Anpassung der Inhalte mal abgesehen, keinen allzu großen Aufwand erfordert.
Meine Contentbär-Standardprogramm
- Contentbär Ranking-123
- Kleine Geschichte in der PZ
- 0815 Blabla bei Gerech.net
- Technischen Infos bei Schnurpsel
- Contentbär um kinuschar Sbrecha
- Adobe Stock Contentbär-Foto
- Wieso, weshalb, warum
Contentbär Ranking-123
Der erste Programmpunkt ist die serverseitige Konfiguration meines Ranking-Monitors „Ranking 123“. Klar, die Rankingdaten sollen möglichst von Anfang an erfaßt werden. Leider hatte ich erst ein paar Tage nach dem Start vom Contentbär-Preisausschreiben erfahren, so das die ersten Tage bei den Daten fehlen.
Wenn die Erfassung läuft, kümmere ich mich um die Anzeige der Daten auf der Ranking-123-Website.
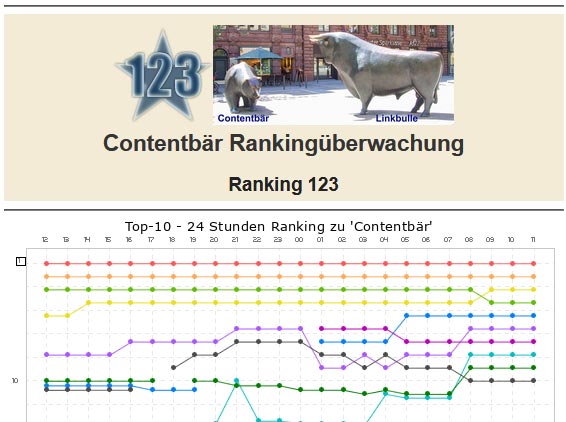
Contentbär Ranking-123
Hier entsteht auch schon das erste Bild, da ich im Header der Seite neben dem 123-Stern in der Regel ein thematisch passendes Bild einbinde. Je nach Suchbegriff kann das ein mehr oder weniger kreatives Foto sein.
Gerne greife ich auf schon vorhanden Bilder zurück und da fielen mir nur deren zwei in meiner Bildersammlung ein. Zum einen ein richtiger Braunbär im Schweriner Zoo und zum anderen der Bär (neben dem Bullen) auf dem Börsenplatz in Frankfurt am Main.
So war die Idee mit „Contentbär gegen Linkbulle“ schnell geboren und mit dem Bild umgesetzt.
Kleine Geschichte in der Putzlowitscher Zeitung
Als nächstes schreibe ich in der PZ eine kleine Geschichte zum Thema, in diesem Fall wie oben bereits erwähnt: Contentbär gegen Linkbulle. Hier geht es vordergründig gar nicht um den SEO-Wettbewerb, eher um eine erdachte Story mit Bezug zu meinem Leben.
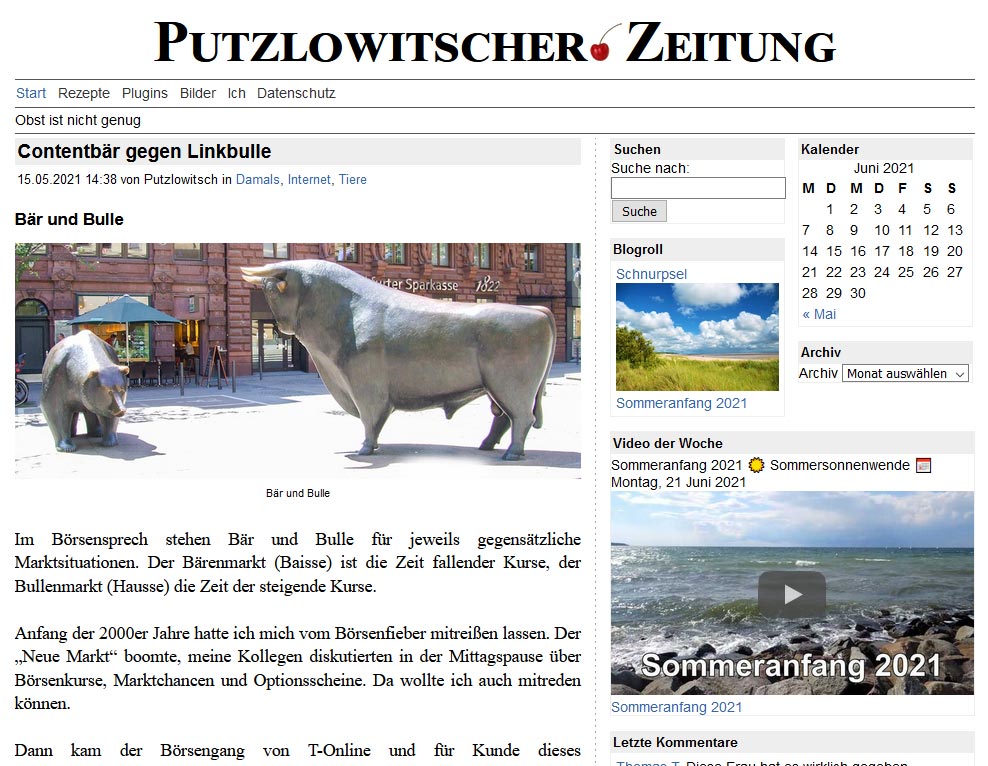
Contentbär in der Putzlowitscher Zeitung
Da ich Anfang der 2000er Jahre getrieben von der Euphorie des „Neuen Marktes“ Aktien gekauft und verkauft habe, hat der erste Teil des Artikels gar nichts mit dem Contentbär zu tun. Erst zum Ende schreibe ich etwas über den Kampf des Contentbären gegen den Linkbullen und den Bezug zur Suchmaschinenoptimierung.
0815 Blabla bei Gerech.net
Meine älteste SEO-Wettbewerb-Website gab es 2005 bei gerech.net. Zu Zeiten der Hommingberger Gepardenforelle hatte ich dort eine Seite mit handgeschriebenem HTML aufgesetzt. Immerhin bin ich damit bei MSN-Search (jetzt Bing) in die Top-10 gekommen.
Dann dümpelte die Website längere Zeit vor sich hin, bis ich sie dann 2011 zum Simsalaseo-Bildersuche-Wettbewerb wieder reaktiviert habe. Seitdem erscheinen dort eher spammige Artikel zu Google-Doodles oder eben zu SEO-Wettbewerben.
Contentbär bei gerech.net
Die letzten Wettbewerbe habe ich hier nach „Schema F“ abgehandel, so auch die Contentbär-Competition. Allgemeine Einleitung zum Start mit den Bedingungen und Preisen, dann Bilder und Videos, schließlich noch Rezept, eigene und Keyword-Domain-Rankings und ein bißchen Blabla, alles auf einer Seite.
Das Rezept habe ich diesmal auf eine eigene Seite ausgelagert. Ob das eine so gute Idee war, weiß ich noch nicht. Den Text in komischer Sprache habe ich auch ausgelagert, dazu später mehr.
Alles in allem zwar viel Text, aber wenig Inhalt. :-)
Blog-Artikel mit technischen Infos bei Schnurpsel
Weiter geht es hier bei Schnurpsel, auch erstmal nach Schema-F. Den Anfang macht der Hinweis auf die maschinenlesbaren Contentbär-Rankingdaten von Ranking-123. Damit könnt ihr die aktuellen Google-Rankings z.B. auf eurer Webseite darstellen. Je nach verwendetem CMS müßten da ein paar Zeilen programmiert werden. Für WordPress gibt es dafür von mir ein Plugin, jetzt in einer verbesserten Version. Das wird aber Inhalt meines nächsten Artikels hier werden.
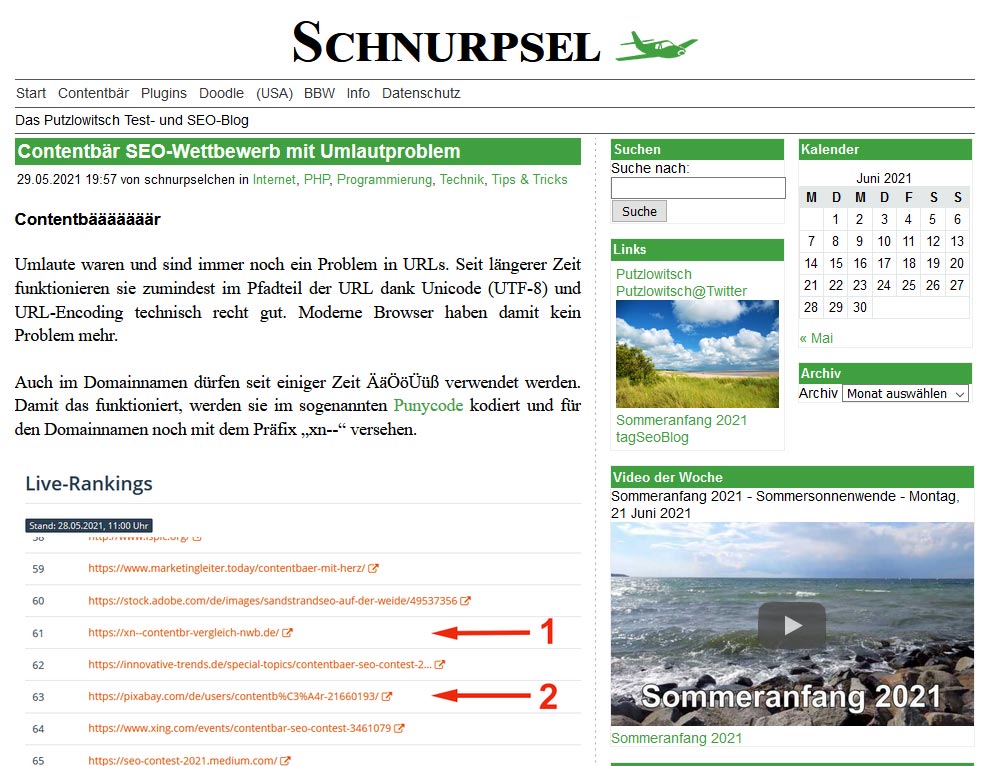
Contentbär mit Umlautproblem
Ein willkommenes Fressen ist natürlich der Umlaut „ä“ im Suchbegriff Contentbär, denn selbst im Jahr 2021 führt das bisweilen immer noch zu Problemen. Auch ich hatte bei Ranking-123 damit Probleme, die ich recht schnell beheben konnte. Bei der offizielle Ranking-Anzeige auf der Seite des Veranstalters wurde das Problem noch nicht beseitigt. Dabei ist es wirklich nicht soooo schwer.
Den einen oder anderen Blogbeitrag zum Thema Contentbär wird es hier noch geben.
Contentbär um kinuschar Sbrecha
Schon seit einiger Zeit experimentiere ich mit Buchstabenvertauschungen. Normale Begriffe ergeben dadurch oft bisher noch nicht existierende Wörter und diese dienen mir dann als Kontroll-Suchbegriffe. Zudem ergeben längere Texte eine Art Blindtext, dem bekannten „Lorem ipsum dolor sit amet…“ nicht unähnlich. Hier ersetze ich dann aber das verbuchselte Keyword mit dem richtigen Keyword und fertig ist der Text in komischer Sprache.

Cimtamtpör um kinuschar Sbrecha
Da ich keine Lust habe, erstmal lange Text zu schreiben um diese nachher zu verbuchseln, benutze ich vorhandene Text. Teilweise sind das eigene Texte, aber auch Inhalte aus der „MS Encarta 2005“, wie hier beim Artikel über Großbären.
Adobe Stock Contentbär-Foto
Seit ein paar SEO-Wettbewerben schicke ich als Gimmick immer wieder ein Adobe-Stock-Foto ins Rennen. Angefangen hatte ich damit, als Fotolia komplett von Adobe übernommen worden war.
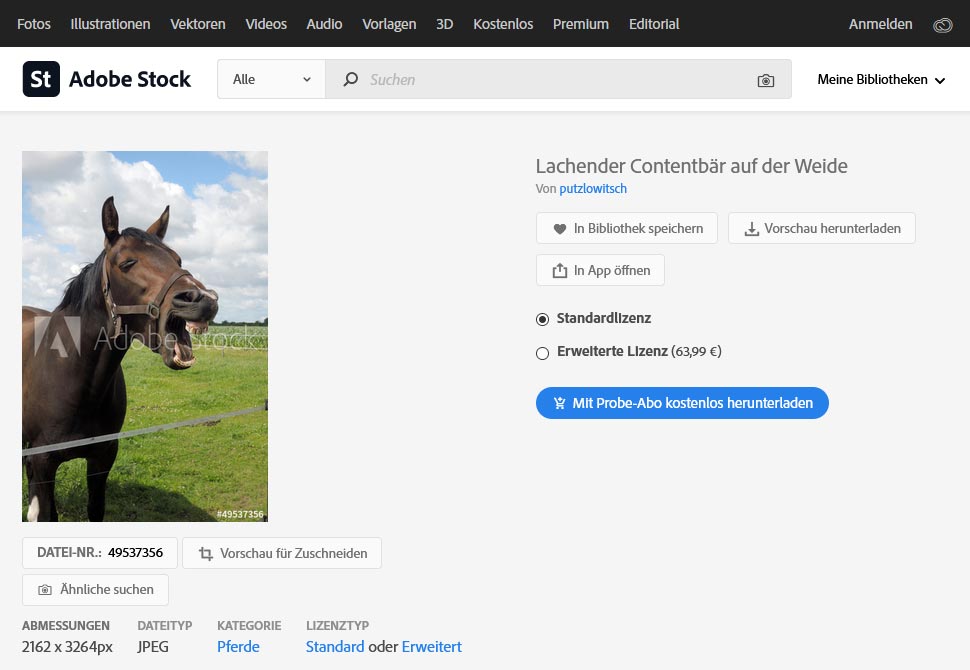
Contentbär bei Adobe-Stock
Bei Fotolia war es praktisch nicht möglich, für zugelassene Bilder nachträglich den Titel, den beschreibenden Text oder die Stichwörter zu ändern. Bei Adobe-Stock ist das hingegen gar kein Problem und so habe ich mein altes Pferd einfach in „Lachenden Contentbär auf der Weide“ umgetauft. Daß ein Pferd kein Bär ist, spielt dabei keine Rolle. Zumindest ist das Foto aktuell mein bestplatziertes Suchergebnis im Contentbär-Wettbewerb.
Meine Contentbär-Rankings vom Montag, 14.06.2021 11:00 Uhr:
| 41 | ⇗ stock.adobe.com/de/images/la...ntbar-auf-der-weide/49537356 |
| 107 | ⇗ ranking-123.de/contentbaer/ |
| 110 | ⇗ schnurpsel.de/nacht/contentbaer/ |
| 112 | ⇗ putzlowitsch.de/2021/05/15/contentbaer-gegen-linkbulle/ |
Und man kann das Foto auch bei Anbietern von Postern oder Fototapeten kaufen, z.B. hier:
Das liegt daran, daß diese Anbieter auf den Bilderbestand von Adobe-Stock per API-Suche zurückgreifen. Alles was bei Adobe gefunden wird, kann man sich dort auch ausdrucken lassen.
Wieso, weshalb, warum
Gut, wirklich teilnehmen tue ich am Contentbär-Contest nicht, weil ich mich nicht angemeldet/registriert habe. Ich probiere einfach aus, was noch wie gut funktioniert oder nicht.
Ich setze hier tatsächlich auf Inhalte und betreibe praktisch kein Linkbuilding. Allerdings gehe ich davon aus, das Links immer noch eine sehr wichtige Rolle spielen. Insofern hat der Linkbulle wohl gegen den Contentbär gewonnen.

Contentbär und Linkbulle