Contentbääääääär
Umlaute waren und sind immer noch ein Problem in URLs. Seit längerer Zeit funktionieren sie zumindest im Pfadteil der URL dank Unicode (UTF-8) und URL-Encoding technisch recht gut. Moderne Browser haben damit kein Problem mehr.
Auch im Domainnamen dürfen seit einiger Zeit ÄäÖöÜüß verwendet werden. Damit das funktioniert, werden sie im sogenannten Punycode kodiert und für den Domainnamen noch mit dem Präfix „xn--“ versehen.
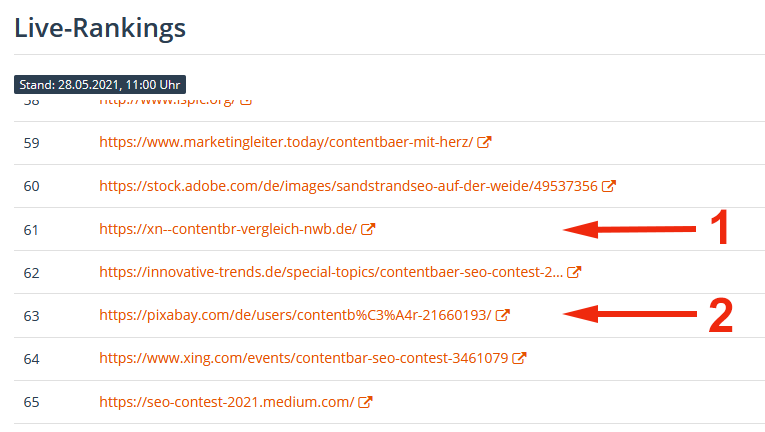
Contentbär Live-Ranking mit Umlautproblem
So sieht das dann z.B. im Contentbär-Liveranking aus, wenn man das für die Darstellung nicht zurück konvertiert.
Sowohl Beispiel 1 „xn--contentbr-vergleich-nwb.de“ als auch Beispiel 2 „/contentb%C3%A4r-21660193/“ sind nicht wirklich gut lesbar. Dabei ist die Umsetzung in lesbaren Text für die Anzeige je nach verwendeter Programmiersprache recht einfach. In PHP z.B. gibt es dafür die Funktionen
idn_to_utf8() urldecode()
Auch bei meinem Contentbär Ranking-123 hatte ich mit dem Problem zu tun, obwohl es nicht der erste SEO-Contest mit Umlauten im Keyword ist. Bereits 2011 träumte so mancher SEO seine Kubaseoträume. Damals gab es meine Seite Ranking-123 in der Form aber noch nicht.
Wie auch immer, ich habe die entsprechenden Anpassungen am PHP-Code vorgenommen und nun werden die Umlaute ordentlich dargestellt.
| 6 | ⇗ contentbär-vergleich.de/ |
| 68 | ⇗ www.reddit.com/r/contentbaer...np39ws/contentbär_halbzeit/ |
| 88 | ⇗ de.quora.com/wie-gewinnt-man...für-den-begriff-contentbär |
| 118 | ⇗ pixabay.com/de/users/contentbär-21660193/ |
| 131 | ⇗ podcasts.apple.com/mx/podcas...ntest-2021/id1567047693?l=en |
| 140 | ⇗ www.amazon.de/contentbär-b�...ttbewerb-ebook/dp/b095frs3zg |
| 149 | ⇗ contentbär-seogewinnspiel.de/produkt/contentbaer/ |
Das sind aktuell (Montag, 14.06.2021 11:00) alle URLs im Ranking, die den Contentbär mit ä enthalten. Sind gar nicht so viele, an die echten Umlaute traut sich kaum jemand ran. Immerhin gibt es aber mit contentbär-vergleich.de eine Umlautdomain im Ranking.
Contentbär Keyword-Domain mit oder ohne Umlaut?
Mal davon abgesehen, daß dem Vernehmen nach Keyword-Domains keinen Rankingvorteil mehr haben, werden sie gerade bei SEO-Wettbewerben immer noch gerne verwendet. Warum das so ist, keine Ahnung.
Bei einem Umlaut im Suchbegriff stellt sich nun die Frage, was als Keyworddomain betrachtet werden kann. Gut, Contentbär mit „ä“ ist ja exakt der Suchbegriff, also wäre z.B. contentbär.de in jedem Fall eine EMD (Exact-Matsch-Domain).
Aber was ist mit der durchaus gebräuchlichen Ersetzung ä => ae? Streng genommen ist das keine Keyword-Domain, weil der Suchbegriff ja nicht genau so im Domainnamen vorkommt. Allerdings sind diese Umlautumschreibungen sehr verbreitet und daher auch beliebt.
Aktuell findet man im Contentbär-Ranking folgende Keyword-Domains (EMD, PMD, EMS und PMS):
| 6 | ⇗ contentbär-vergleich.de/ |
| 34 | ⇗ contentbaer-in.jimdosite.com/ |
| 38 | ⇗ contentbaer.myportfolio.com/ |
| 48 | ⇗ contentbaer.wordpress.com/ |
| 56 | ⇗ contentbaer.puzl.com/ |
| 62 | ⇗ contentbaer-in.weebly.com/ |
| 67 | ⇗ www.contentbaer.com/ |
| 109 | ⇗ dercontentbaer.de/ |
| 125 | ⇗ contentbaer-contest.de/ |
| 142 | ⇗ contentbaer.rocks/ |
| 148 | ⇗ contentbaerseo.de/ |
| 149 | ⇗ contentbär-seogewinnspiel.de/produkt/contentbaer/ |
| 152 | ⇗ contentbaeren.de/nahrung |
| 156 | ⇗ contentbaer-gewinner.de/ |
| 157 | ⇗ www.contentbaer-seocontest.com/ |
| 159 | ⇗ www.contentbaer-seo.com/ |
Da findet man nur eine echte Umlautdomain, den oben schon erwähnten Contentbär-Vergleich, alle anderen setzen auf die „ä -> ae“-Substitution, sei es nun Domain oder Subdomain. Vielleicht sollte ich mal wieder meine keintext-Subdomain an den Start bringen, mit echtem Umlaut natürlich.
Na mal sehen, was daraus wird…
(Cimtamtpör)