Früher war alles besser

Bildersuche Referrer
Um zu erkennen, ob der Besucher einer Seite über die Bildersuche kommt, konnte man lange Zeit den Referrer auswerten. Dort fand man bestimmte Parameter (z.B. /imgres), die auf einen Treffer aus der Bildersuche schließen ließen.
Seit der Einführung der neuen Bildersuche bei google.de fehlen diese Parameter im Referrer und es steht bestenfalls noch „https://www.google.de/“ drin.
Bei vielen Websitebetreibern [1] [2] [3] führte das zu dem Schluß, daß nun von der Bildersuche praktisch gar keine Besucher mehr kommen. Es handelt sich aber um ein „Meßfehler“ in Google-Analytics, weil die alten Methoden zum tracken der Bildersuche nun nicht mehr funktionieren.
Die neue Bildersuche hat aber diesbezüglich einen positiven Aspekt, denn vor dem Besuch der Seite, wenn es denn dazu kommt, wird das Original-Bild vom Server abgerufen.
Tracking mit Keksen

Kekse – Cookies (Foto: ajt / 123RF)
Wie hilft uns das nun bei der Erkennung von Besuchern aus der Bildersuche?
Beim Abruf des Bildes kann ein Cookie gesetzt werden, das dann beim Aufruf der Seite ausgewertet wird. Gut, falls jemand Cookies deaktiviert hat, funktioniert das natürlich nicht, aber so viele Nutzer von Suchmaschinen werden das nicht sein.
Auch früher gabe es schon nutzerbedingte Meßfehler. Hat der Nutzer z.B. die Übertragung des Referrers ausgeschaltet, konnten die Zugriffe nicht zugeordnet werden. Hat der Nutzer gar JavaScript deaktiviert oder blockiert z.B. per DNS die Zugriffe auf www.google-analytics.com, wurden überhaupt keine Pageviews registriert.
Ich selbst bin ja eher ein Anhänger der Logfile-Analyse und verwende kein Google-Analytics oder andere Tools. Die Logfiles werden ohnehin erzeugt und da steht tatsächlich jeder Zugriff drin. Die richtige Interpretation der Daten ist dann allerdings auch schon eine Kunst für sich.
Zugriff!

Bildersuche-Tracking in der .htaccess
Fast alle Aktionen, die wir für das Tracking per Cookie benötigen, können in der .htaccess-Datei erledigt werden. Für das Tracking mit Google-Analytics wird ein angepaßter JavaScript-Code erzeugt.
Die technische Basis meiner Lösung ist ein Apache-Webserver mit den aktiven Modulen mod_rewrite und für das Tracking in der Server-Logatei mod_headers.
Der für das Tracking verantwortliche Teil meiner .htaccess sieht so aus:
<IfModule mod_headers.c>
RequestHeader merge Referer "bisutrk=%{BISU_TRK}e" env=BISU_TRK
</IfModule>
<IfModule mod_rewrite.c>
RewriteEngine On
# Aufruf eines existierenden Bildes
RewriteCond %{REQUEST_URI} \.(jpg|png|gif)$
RewriteCond %{REQUEST_FILENAME} -f
RewriteRule . - [E=REQ_IMG:1]
# Aufruf einer normalen Seite
RewriteCond %{REQUEST_URI} !\.[^\.]+?$
RewriteRule . - [E=REQ_PAGE:1]
# Host-Domain
RewriteCond %{HTTP_HOST} (([^\.]+?\.)?[^\.]+?)$
RewriteRule . - [E=OWN_DOM:%1]
# Referrer-Domain
RewriteCond %{HTTP_REFERER} ^https?://(([^\.]+?\.)?([^\.]+?\.)?[^\.]+?)/
RewriteRule . - [E=REF_DOM:%1]
# Referrer Second-Level-Domain (SLD) ist google oder bing
RewriteCond %{ENV:REF_DOM} (google|bing)(\.(com|co))?\.[^\.]+?$ [NC]
RewriteRule . - [E=REQ_SLD:%1]
# Bild -> Cookie setzen
RewriteCond %{ENV:REQ_IMG} 1
RewriteCond %{ENV:REQ_SLD} ^(.+?)$
RewriteRule . - [CO=BiSuTrk:%1:.%{ENV:OWN_DOM}]
# Normale Seite und Cookie gesetzt -> Variable setzen und Cookie löschen
RewriteCond %{ENV:REQ_PAGE} 1
RewriteCond %{ENV:REQ_SLD} ^(.+?)$
RewriteCond %{HTTP_COOKIE} BiSuTrk=([^;]+?)(;|$) [NC]
RewriteRule . - [E=BISU_TRK:%1,CO=BiSuTrk:INVALID:.%{ENV:OWN_DOM}:-1]
</IfModule>
Das sieht vielleicht erstmal etwas kompliziert aus, ist es aber nicht. Es sind auch noch Vereinfachungen möglich.
Die Anweisungen bewirken kein Rewrite und dienen nur zum Setzen und Auswerten von Umgebungsvariablen und zum Setzen bzw. Löschen von Cookies. Der Block sollte vor allen anderen Rewrite-Regeln stehen.
# Aufruf eines existierenden Bildes
RewriteCond %{REQUEST_URI} \.(jpg|png|gif)$
RewriteCond %{REQUEST_FILENAME} -f
RewriteRule . - [E=REQ_IMG:1]
An Hand der Dateierweiterung wird geprüft, ob ein Bild angefordert wird. Außerdem wird getestet, ob es das Bild als Datei gibt. Falls nicht, soll der Zugriff auch nicht getrackt werden. Treffen beide Bedingungen zu, wird das in der Umgebungsvariablen REQ_IMG vermerkt. Diese wird dann später ausgewertet.
# Aufruf einer normalen Seite
RewriteCond %{REQUEST_URI} !\.[^\.]+?$
RewriteRule . - [E=REQ_PAGE:1]
Das eigentliche Tracking soll nur beim Aufruf einer normalen Seite erfolgen. Naheliegend wäre, daß man die Bedingung „Ist ein Bild“ einfach umkehrt, also negiert. Das trifft aber nicht immer zu, denn je nach Webbrowser wird nach dem Bild zum Beispiel noch das Favoriten-Icon favicon.ico abgerufen. Dieser Aufruf würde dann bereits das Tracking auslösen, was nicht gewollt ist.
Hier muß also eine Regel formuliert werden, die einen normalen Seitenaufruf beschreibt. In meinem Fall sind es die Permalinks von WordPress, die sich dadurch von normalen Dateiaufrufen unterscheiden, daß sie keine Dateiwerweiterung wie z.B. .jpg, .ico oder .css haben.
Wenn normale Seiten immer auf .html enden, könnte die Regel z.B. so aussehen:
RewriteCond %{REQUEST_URI} \.html$
RewriteRule . - [E=REQ_PAGE:1]
# Host-Domain
RewriteCond %{HTTP_HOST} (([^\.]+?\.)?[^\.]+?)$
RewriteRule . - [E=OWN_DOM:%1]
Hier wird aus dem HTTP_HOST der Domainname ohne Subdomain bzw. vorangestelltem www extrahiert. Die Variable wird als Cookie-Domain verwendet. Man kann die Domain aber auch direkt bei den beiden Cookie-Aktion eintragen. Ich wollte das Ganze nur so weit wie möglich universell gestalten.
# Referrer-Domain
RewriteCond %{HTTP_REFERER} ^https?://(([^\.]+?\.)?([^\.]+?\.)?[^\.]+?)/
RewriteRule . - [E=REF_DOM:%1]
Hier wird aus dem HTTP_REFERER der Domainname der aufrufenden URL extrahiert. Da ich den Referrer-Domainnamen noch bei anderen Rewrite-Regeln benötige, ziehe ich mir den an einer Stelle raus und packe ihn in eine Umgebungsvariabel. Das kann man auch anders machen bzw. mit der nächsten Regel zusammenfassen.
# Referrer Second-Level-Domain (SLD) ist google oder bing
RewriteCond %{ENV:REF_DOM} (google|bing)(\.(com|co))?\.[^\.]+?$ [NC]
RewriteRule . - [E=REQ_SLD:%1]
Nun wird mit der eben extrahierten Referrerdomain geprüft, ob es sich um Google oder z.B. Bing handelt und der Treffer ggf. in einer Umgebungsvariablen abgelegt. Berücksichtigt wird auch, daß es in manchen Ländern noch die Ebene .com und .co vor der eigentlichen Second-Level-Domain (SLD) gibt (z.B. google.co.uk oder google.com.au).
# Bild -> Cookie setzen
RewriteCond %{ENV:REQ_IMG} 1
RewriteCond %{ENV:REQ_SLD} ^(.+?)$
RewriteRule . - [CO=BiSuTrk:%1:.%{ENV:OWN_DOM}]
Nach der ganzen Vorarbeit kommen wir nun endlich zum Kernpunkt, dem Setzen eines Tracking-Cookies. Ich habe ihm den Namen BiSuTrk (Bilder-Suche-Tracking) verpaßt.
Die Bedingungen und Regeln sind einfach erklärt. Haben wir es mit einem existierenden Bild zu tun (REQ_IMG) und kommt der Aufruf von Google oder Bing (REQ_SLD), dann wird ein Cookie mit dem Namen BiSuTrk und dem Wert google/bing für die eigene Domain (OWN_DOM) gesetzt.
Hier findet Ihr die Beschreibung zur Cookie-Funktion im Apache-Rewrite-Modul. Ich verwende nur die ersten drei Parameter Name, Wert und Domain. Interessant ist aber auch noch der nächste Parameter „Lifetime“, der die Lebenszeit des Cookies in Minuten festlegt. Wird er nicht verwendet oder ist 0, dann wird ein Session-Cookie gesetzt. Das heißt, es überlebt nur, solange der Webbrowser nicht geschlossen wurde.
Falls ein Bild von Google oder Bing aufgerufen wurde, sind wir hier fertig. Das Cookie ist gesetzt und wartet im Hintergund auf den ersten Seitenaufruf.
# Normale Seite und Cookie gesetzt -> Variable setzen und Cookie löschen
RewriteCond %{ENV:REQ_PAGE} 1
RewriteCond %{ENV:REQ_SLD} ^(.+?)$
RewriteCond %{HTTP_COOKIE} BiSuTrk=([^;]+?)(;|$) [NC]
RewriteRule . - [E=BISU_TRK:%1,CO=BiSuTrk:INVALID:.%{ENV:OWN_DOM}:-1]
Der Nutzer hat unser schönes Bild in der Bildersuche gesehen, interessiert sich nun doch für unsere Seite und klickt beherzt auf das Bild oder [Seite besuchen]. Jetzt schlägt die letzte Tracking-Regel zu.
Es ist ein normaler Seitenaufruf (REQ_PAGE) und er kommt von google/bing (REQ_SLD) und das Tracking-Cookie ist gesetzt (HTTP_COOKIE). Yeahhh, dann ist es mit hoher Wahrscheinlichkeit ein Besucher aus der Bildersuche. Das merken wird uns in der Umgebungsvariable BISU_TRK und löschen das Cookie. Wobei man ein Cookie nicht löschen, sondern nur für ungültig erklären kann. Das passiert über eine Verfallszeitpunkt in der Vergangenheit, hier konkret mit -1 Minute.
Ab in die Log-Datei
Da der Referrer uns nicht mehr wie früher die Informationen zur Bildersuche liefert, setzen wird die Trackinginformation einfach in den Referrer ein.
<IfModule mod_headers.c>
RequestHeader merge Referer "bisutrk=%{BISU_TRK}e" env=BISU_TRK
</IfModule>
Mit dem Headers-Modul des Apache-Webservers kann man auch die Request-Header verändern, also das was eigentlich vom Browser des Nutzers gesendet wird. Abhängig davon, ob die Umgebungsvariable TRK_VALUE gesetzt ist, wird der Wert dem Referer hinzugefügt und landet so im Server-Logfile.
... "GET /tomaten/ HTTP/1.1" 200 8061 "http://www.google.de, bisutrk=google"
So sieht das dann im Logfile aus. Der Parameter wird mit Komma und Leerzeichen an den vorhandenen Referrer angehängt.
Wie man das nun auswertet, hängt von der verwendeten Logfile-Analyse-Software ab. Bei meinen selbst geschriebenen PHP-Skripten war das natürlich kein Problem.
Ab zu Google-Analytics
Da ich selbst kein Google-Analytics (GA) verwende, kann ich das nicht testen, theoretisch sollte es aber wie beschrieben funktionieren.
Man kann in GA benutzerdefinierte Parameter verwenden. Es gibt Dimensions und Metrics. Der normale Funktionsaufruf zum Tracking eines Seitenaufrufs sieht so aus.
ga( 'send', 'pageview' );
Mit einer benutzerdefinierten Dimension könnte das dann so aussehen:
ga( 'send', 'pageview', { 'dimension15': 'google' } );
Wie man das nun auf der Webseite ausgibt, hängt vom CMS ab. Als einfaches Beispiel habe ich das hier mal als PHP-Codeschnipsel implementiert:
$bisu_trk = trim( $_SERVER['BISU_TRK'] );
if( $bisu_trk )
echo "ga( 'send', 'pageview', { 'dimension15': '$bisu_trk' } );";
else
echo "ga( 'send', 'pageview' );";
Es wird die in der .htaccess-Datei gesetzte Variable (BISU_TRK) geprüft. Falls diese nicht leer ist, wir der ensprecheden Wert im der Dimension verwendet.
Fehler- und weitere Betrachtung
Ganz hundertprozentig sicher wird dieses Tracking der Bildersuche nicht funktionieren. Wie oben schon erwähnt, setzt es auf Cookies und falls der Nutzer keine Cookies erlaubt, guck man in die Röhre.
Außerdem ist nicht garantiert, daß der Nutzer tatsächlich mit dem Klick aus der Bildersuche kam. Vorstellbar ist, daß er zwar zunächst in der Bildersuche etwas gesucht hat, dann aber zur normalen Suche gewechselt ist und von dort Eure Seite besucht hat.
Selbst wenn der Nutzer Euer Bild in der Bildersuche gar nicht gesehen hat, wird möglicherweise trotzdem das Trackingcookie gesetzt. Das liegt daran, daß Google im Hintergrund bereits das vorhergehende und das nachfolgende Bild lädt.
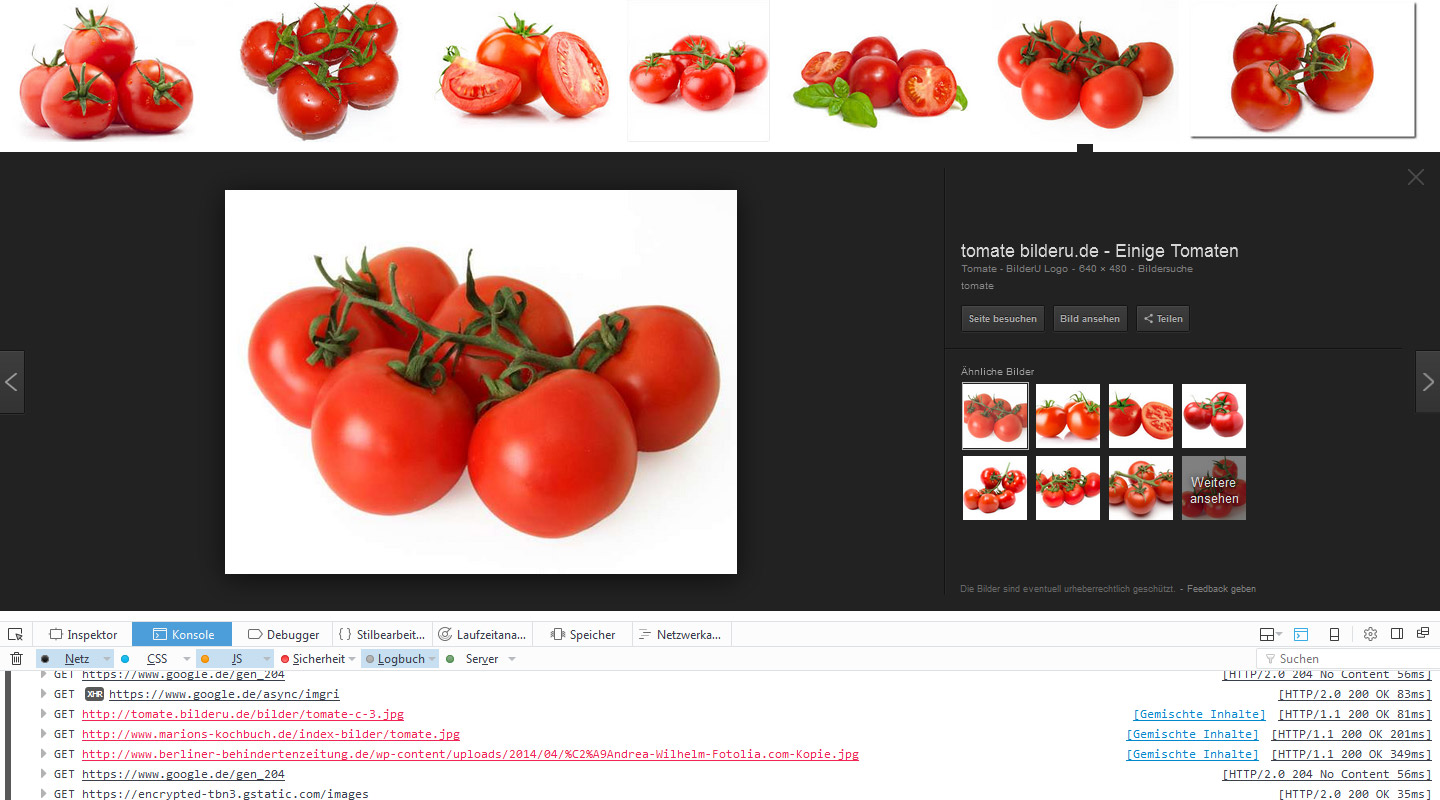
Google-Bildersuche: Neues Layout (Preload)
Man könnte die Lebenszeit des Cookies verkürzen.
RewriteCond %{ENV:REQ_IMG} 1
RewriteCond %{ENV:REQ_SLD} ^(.+?)$
RewriteRule . - [CO=BiSuTrk:%1:.%{ENV:OWN_DOM}:5]
Falls der Nutzer nicht innerhalb von 5 Minuten, nachdem er das Bild gesehen hat, auf die Seite klickt, dann kommt er höchst wahrscheinlich doch nicht über die Bildersuche.
Für das Tracking in der Server-Logdatei benötigt man den ganzen Zauber mit Cookies eigentlich gar nicht, denn da steht ja sowohl der Aufruf des Bildes als auch der Seite drin. Die Frage ist nur, ob und wie man diese Einträge in der Logfileanalyse-Software zusammenbringen kann.
Ende im Gelände?
Auch in der neuen Bildersuche gibt es durchaus Möglichkeiten, die Nutzer der Bildersuche zu erkennen. Mit ein paar technischen „Tricks“ ist das Tracking im Logfile und in Google-Analytics möglich.
Falls jemand von Euch diese Trackingtechniken nutzt, würden mich Euere Erfahrungen damit, besonders bezüglich Google-Analytics, interessieren. Schreibt es in die Kommentare! :-)