
Neue Version!
Eine neue, erweiterte Version gibt es hier:
Google Bilder-Liste – ei...et für die Google Bildersuche
Bookmarklets
Die Bookmarklets sind feine Sachen, denn man kann tolle Dinge damit machen. :-)
Ein Bookmarklet ist ein Browser-Lesezeichen, welches aber nicht die URL einer Webseite speichert, sondern Javascript-Code. Dieser kann dann auf eine gerade im Browserfenster angezeigte Webseite losgelassen werden.
Das Bookmarklet hat Zugriff auf den kompletten Seiteninhalt, kann diesen verändern oder Daten extrahieren und z.B. in einem neuen Fenster darstellen.
Genau Letzteres war der Anlaß, aß ich mich nun mit Bookmarklets beschäftige. Bisher wußte ich noch nicht mal etwas von deren Existenz.
Ein Bookmarklet für die Google Bildersuche
Bei Facebook fragte David Radicke vor einigen Tagen, ob nicht jemand ein Tool/Addon/Bookmarket kennt, mit welchem man in der Google Bildersuche nur die URLs anzeigen kann.
Daraufhin bekam er eine Lösung programmiert. Dieses Bookmarklet von Chris Ainsworth ist schon eine feine Sache. Es extrahiert aus der Ergebnisseite der Google-Bildersuche die URLs der Bilder und der referenzierenden Seiten und zeigt sie in einer übersichtlichen Tabelle an.
Aber zur Bildersuche gehören irgendwie auch die Bilder. Also habe ich das Javascript etwas angepaßt und erweitert:
- in der ersten Spalte werden die Thumbnails und die Bildgröße angezeigt
- das Bookmarklet funktioniert ohne Änderung für alle Google-Länderdomains
- man kann sich eigene Bilder und ggf. fremde Hotlinks farblich hervorheben lassen
Das Ergebnis sieht dann in etwa so aus:

Google Image Extractor with Thumbnails
Hier findet Ihr das Bookmarklet Version 1.1, welches die Tabelle erzeugt:
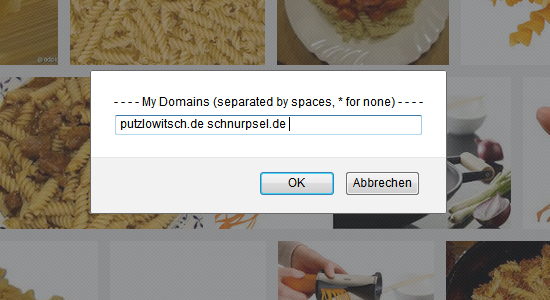
Google Image-Extractor Domains-Config
Hier findet Ihr das Bookmarklet, mit welchem ihr die Liste der eigenen Domains befüllen könnt:
Die Bookmarklets sind zwar Links, es macht aber wenig Sinn, diese hier direkt anzuklicken. Vielmehr müßt Ihr sie als Lesezeichen im Browser speichern, also z.B. einfach in die Bookmarkleiste ziehen.
Dann ruft Ihr die Google-Bildersuche mit dem gewünschten Suchbegriff auf und startet das Bookmarklet durch Anklicken des Lesezeichens (Buttons in der Lesezeichenleiste).
Die Liste der eigenen Domains wird im localStorage gespeichert, der aber nur bei neueren Browsern funktioniert. Zudem müssen Cookies für die Google-Domain erlaubt sein.
Getestet habe ich die Bookmarklets bisher mit Firefox 35.0.1 und Google Chrome 40.0.2214.94, damit funktioniert es.
Die Tests mit anderen Browsern überlasse ich Euch. :-)

{function getQueryVar(url,name){var retval=null;var pos=url.indexOf('?');var query=url.slice(pos+1);var vars=query.split('&');for(var t=0;t<vars.length;t++){var pair=vars[t].split('=');var n=pair.shift();var v=pair.join('=');if(n==name){retval=v;try{retval=decodeURIComponent(retval);try{retval=decodeURIComponent(retval);} catch(e){console.log('getQueryVar->decodeURIComponent (2) - '+e.message+' '+retval);}} catch(e){console.log('getQueryVar->decodeURIComponent (1) - '+e.message+' '+retval);} break;}} return retval;} var domList=[];var domCookie=localStorage.img_extractor_tbn;if(domCookie) domList=domCookie.split(' ');output='<html><head><title>High Position SERP Link Generator</title><style type=\'text/css\'>body,table{font-family:Tahoma,Verdana,Segoe,sans-serif;font-size:11px;color:#000}h1,h2,th{color:#405850}th{text-align:left}h2{font-size:11px;margin-bottom:3px}table.data{table-layout:fixed;width:100%;border-collapse:collapse;}table.data th,table.data td{overflow:hidden;border-bottom:1px solid #9eb8b0;padding:4px;}table.data th.id,table.data td.id {width:30px;}table.data th.img{width:75px;}table.data td.img{width:75px;height:60px;font-size:smaller;text-align:center;}table.data td.img img{max-width:75px;max-height:50px;}table.data th.dom{width:15%;}.mydom{background-color:#c5ffb5;}.hotlink{background-color: #ffb5b5;}</style></head><body>';output+='<h1>Google Image Search URL Extractor with Thumbnails</h1>';pageAnchors=document.getElementsByClassName('rg_l');var linkcount=0;output+='<table class=\'data\'><th class=\'img\'>Thumbnail</th><th class=\'id\'>ID</th><th class=\'dom\'>Image Domain</th><th>Image URL</th><th class=\'dom\'>Source Domain</th><th>Source URL</th>';for(i=0;i<pageAnchors.length;i++){linkcount++;var href=pageAnchors[i].href;var imgurl=getQueryVar(href,"imgurl");var sourceurl=getQueryVar(href,"imgrefurl");var width=getQueryVar(href,"w");var height=getQueryVar(href,"h");var img=pageAnchors[i].getElementsByTagName('img');var img_src=img[0].src;if(!img_src) img_src=img[0].getAttribute('data-src');var imgdom='';var imgdomd='';if(imgurl){arr=imgurl.split('/');imgdom=arr[2];imgdomd=arr[0]+'//'+arr[2];} var refdom='';var refdomd='';if(sourceurl){arr=sourceurl.split('/');refdom=arr[2];refdomd=arr[0]+'//'+arr[2];} var tr='<tr>';var ref_td='<td>';var mydom=false;var hotlink=false;if(domList.length){for(d=0;d<domList.length;d++){if(imgdom.indexOf(domList[d])>-1){mydom=true;hotlink=true;for(e=0;e<domList.length;e++){if(refdom.indexOf(domList[e])>-1){hotlink=false;break;}} break;}}} if(mydom) tr='<tr class=\'mydom\'>';if(hotlink) ref_td='<td class=\'hotlink\'>';output+=tr;var tbn_url='<img src=\''+img_src+'\' /><br />'+width+'x'+height;output+='<td class=\'img\'>'+tbn_url+'</td>';output+='<td class=\'id\'>'+linkcount+'</td>';output+='<td>'+imgdomd+'</td>';output+='<td>'+decodeURI(imgurl)+'</td>';output+=ref_td+refdomd+'</td>';output+=ref_td+decodeURI(sourceurl)+'</td>';output+='</tr>\n';} output+='</table><br/>';output+='<br/><p align=center><a href=\'https://www.highposition.com\'>www.highposition.com</a> <a href=\'https://schnurpsel.de\'><img src=\'https://schnurpsel.de/images/s48x30.png\' /></a></p>';with(window.open()){document.write(output);document.close();}})();){kind=link}