
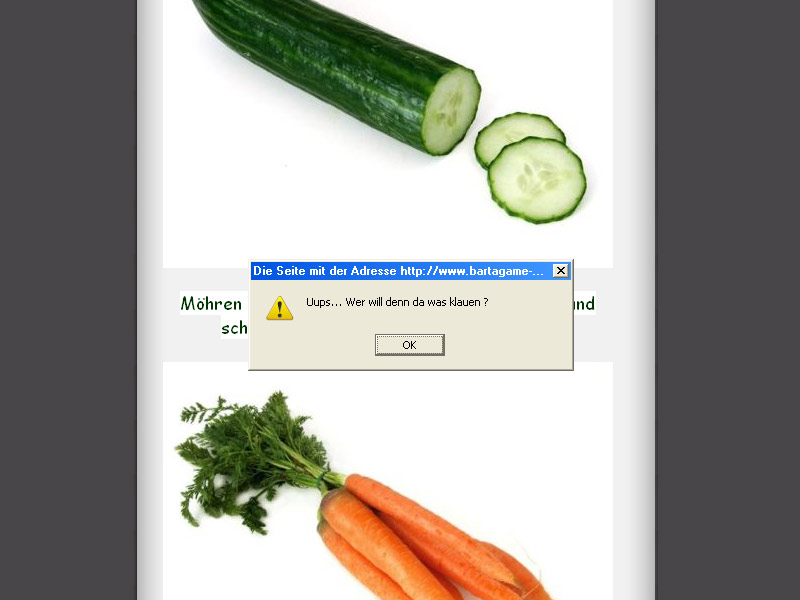
Wenn Besucher über Google auf die eigene Webseite kommen, ist das ja normalerweise eine schöne Sache. Allerdings nicht, wenn es über einen seltsamen Link, wie er oben zu sehen ist, passiert. Wie kommt aber soetwas überhaupt in den Index einer Suchmaschine?
Das gibts doch gar nicht
Bereits im Oktober letzen Jahres hatte ich etwas Ähnliches beobachtet. Da wurden Google massiv mit Links auf irgendwelche nicht existierende Seiten gefüttert. Wenn nun eine dieser nicht vorhandenen Seiten auf die Anfrage des Googlebots einen HTTP-Status „200 OK“ zurückliefert, geht Google davon aus, daß es die Seite gibt und nimmt sie in den Index auf. Korrekterweise sollte aber mit dem Fehlerstatus „404 Not found“ geantwortet werden, so daß die Seite nicht im Index landet. Genau das war damals bei mir der Fall, also ist eigentlich alles in Butter. Nur habe nicht mit der Großzügigkeit von WordPress gerechnet.
Die WordPress.presse.pressung
In manchen Dingen ist WordPress recht großzügig. Früher war es möglich, wenn in den Permalinks die Artikel ID verwendet wurde, einen Artikel über nahezu beliebig viele URLs aufzurufen. Sobald die ID erkannt wurde und existierte, wurde der Rest der URL nicht weiter überprüft. So hätte man diesen Beitrag hier auch noch mit /alles-quark-399/ oder /blafasel-399/ aufrufen können. Das geht mittlwerweile nicht mehr. Allerdings ist zur Zeit etwas Ähnliches immer noch möglich, wenn man in den Permalinks die Kategorie verwendet.
Wenn nun eine WordPress-Seite mit Parametern in der Form /?parameter=wert aufgerufen wird, ignoriert WordPress einfach unbekannte Patemeter oder ungültige Paremeterwerte und tut so, als würde es diese Parameter gar nicht geben. Somit führen folgende Aufrufe zu gültigen Seiten:
http://testblog.schnurpsel.de/?q=Diese Seite gibt es nicht
http://testblog.schnurpsel.de/?quark=Gesund und schmeckt lecker
http://testblog.schnurpsel.de/?p=Hier steht normalerweise die ID
Bei den ersten beiden Beispielen wir ein unbekannter Paremeter verwendet, im dritten Beispiel der gültige Parameter p= (Short-Link), der allerdings eine numerische Artikel-ID erwartet. In allen Fällen wird die Startseite mit dem Status „200 OK“ angezeigt. Es funktioniert aber ebenso mit Einzelseiten oder anderen Permalinks:
http://testblog.schnurpsel.de/...hallo-welt/?frage=was-soll-das
http://testblog.schnurpsel.de/2010/03/?jahreszeit=Frühling
Gut oder schlecht
Ob dieses Verhalten von WordPress nun gut oder schlecht, gewollt oder ein Fehler ist, mag ich nicht beurteilen. Ich finde es zumindest suboptimal, denn dadurch entstehet z.B. die oben gezeigte URL als Google-Treffer, und sowas möchte ich nicht haben. Dabei wäre es für WordPress kein größeres Problem, unbekannte Parameter oder ungültige Parameterwerte als Fehler zu behandeln. Das schöne an WordPress ist ja, daß es recht einfach erweitert und modifiziert werde kann.
Fehler bleibt Fehler
Deshalb habe ich mir diese Parameterprüfung hier nachgerüstet (aber nicht für den Testblog!), übrigens auch für die worpdresseigene Suchfunktion. Denn falls es keinen Suchtreffer gibt, finde ich, ist das auch einen „404 Not Found“ wert :-)
Nun sollte auch die ganz oben gezeigte, hier nicht existierende Seite nach einiger Zeit aus dem Suchindex verschwinden.
Nachtrag:
Weil es angefragt wurde, hier mein Code zur Parameterprüfung, der sich per Action-Hook in parse_request reinhängt:
<?php
function plw123_parse_request( $data ) {
// Liste der numerischen Parameter
$num_para = array( 'p', 'page_id', 'attachment_id', 'tag_id',
'page', 'paged',
'year', 'monthnum', 'day', 'w', 'm',
'hour', 'minute', 'second' );
// Parameter übergeben, aber nicht gefunden
foreach( $_GET as $key => $value )
if( !array_key_exists( $key, $data->query_vars ) ) {
$data->query_vars['error'] = '404';
return;
}
// Numerische Parameter prüfen
foreach( $data->query_vars as $key => $value ) {
// Sonderbehandlung Kategorie-IDs
if( 'cat' == $key ) {
// darf eine Liste von kommaseparierten Integerwerten sein
$test_value = preg_replace( '|[^0-9,-]|', '', $value );
if( $test_value != $value ) {
$data->query_vars['error'] = '404';
return;
}
}
// Numerische Werte
if( in_array( $key, $num_para ) ) {
$value = trim( $value );
// Page bei Einzelansicht (Seite, Artikel) kann führenden Slash enthalten
if( 'page' == $key )
$value = ltrim( $value, '/' );
$test_value = absint( $value );
if( !$test_value ) {
$data->query_vars['error'] = '404';
return;
}
}
}
}
add_action( 'parse_request', 'plw123_parse_request' );
?>
Habe das jetzt mal erweitert und in ein Plugin gepackt: 123 Prameter Check



{kind=link}