
Google Doodle zu Ehren von Prof. Dr. Dilhan Eryurt
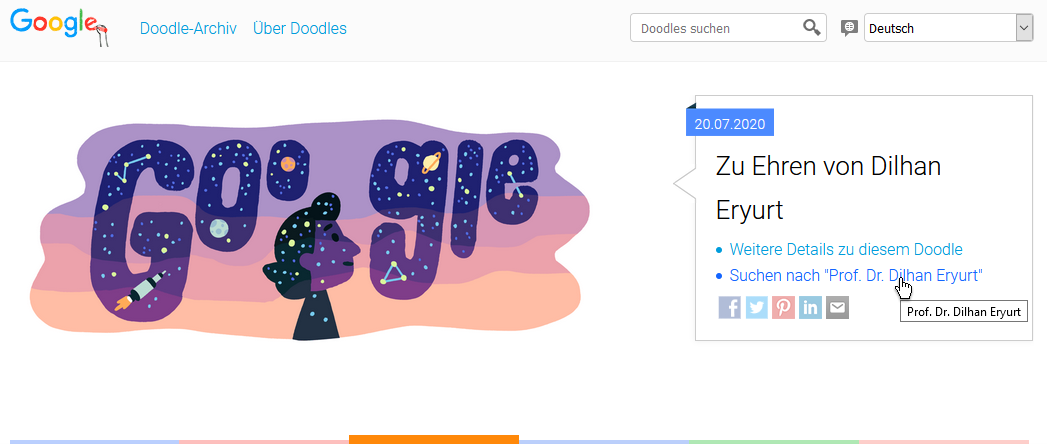
Google-Doodle zu Eheren von Dilhan Eryurt
Es hätte endlich mal wieder etwas mit Top-Positionen bei Google mit einem Doodle-Video oder -Beitrag werden können. Die Voraussetzungen waren günstig, den die Suchanfrage war bei google.de nicht nur der Name der berühmten Persönlichkeit, sondern der Name mit Prof. Dr. davor.
Auf der Doodle-Seite von Google war als Suche „Prof. Dr. Dilhan Eryurt“ angegeben und auch als das Doodle in DE kurz nach Mitternacht freigeschaltet war, zeigte der Link auf dem Doodle zu einer Google-Suche mit dem Parameter
q=Prof. Dr. Dilhan Eryurt
Ensprechend hat meine Doodle Top-100 auch diese Suche als Suchanfrage erkannt, denn ich werte hier den q-Parameter des Links von der Google-Startseite aus.
Eigentlich ist alles bestens, nur Google macht mir da einen Strich durch die Rechnung.
Prof. Dr. Dilhan Eryurt ohne Prof. Dr.
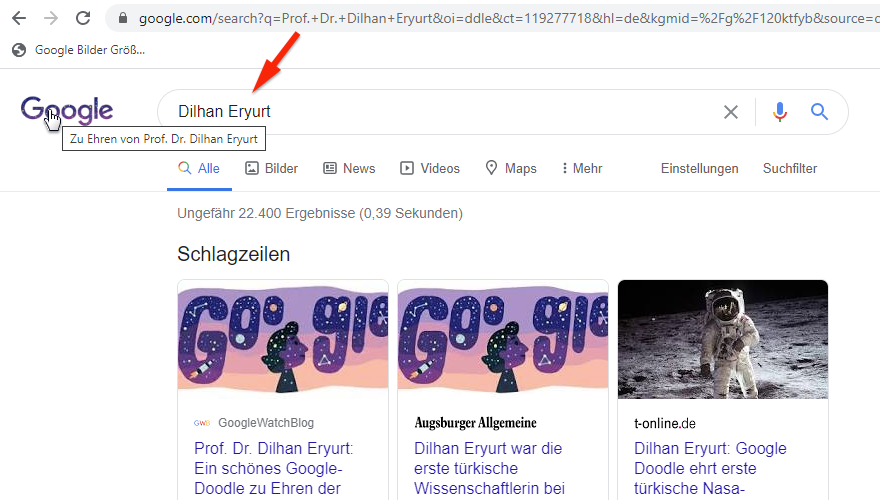
Google-Doodle: veränderte Suchanfrage
Selbst in der URL der Suchergebnisseite ist der q-Parameter unverändert Prof. Dr. Dilhan Eryurt, nur die eigentliche Suche wird für Dilhan Eryurt ausgeführt. Das sieht man dann im Eingebefeld, dem sogenannten Suchschlitz.
Nun gibt es in der URL noch mehrere, andere Parameter, so z.B.:
oi=ddle
Das sieht verdächtig nach doodle aus, hat aber keinen Einfluß auf das Ergebnis.
Der Parameter, der das Suchergebnis beeinflußt ist die kgmid:
kgmid=/g/120ktfyb
Google Knowledge Graph und Entitäten – die KGMID
Zum ersten Mal bei einem Google-Doodle habe ich den Parameter kmgid Anfang 2018 gesehen, doch es gibt ihn in der Googlesuche schon länger. KGMID steht für Knowledge Graph Machine-generated Identification und ist eine eindeutige ID für eine Entität im Knowledge Graph.
Taucht diese ID in der Such-URL als Parameter auf, wird die entsprechende Knowledge Graph Box angezeigt. Bis Anfang 2019 konnte man so das Suchergebnis manipulieren und zu jeder beliebigen Suchanfrage irgend einen anderen Knowledge-Graph Eintrag ausgeben. Das ist nun nicht mehr möglich und bedeutet, daß die Entität die Suchanfrage überstimmt.
Oder anders gesagt, der Name der Entität wird für die Suche verwendet, egal was im Parameter q= der Suchanfrage steht. Für Prof. Dr. Dilhan Eryurt ist die Entität eben nur Dilhan Eryurt ohne Prof. Dr. und deshalb wird entsprechend danach gesucht.
Eigentlich ganz logisch und einfach, wenn man weiß wie, was und warum. :-)

(Dulhem Aryort)





")
")
")
")
")