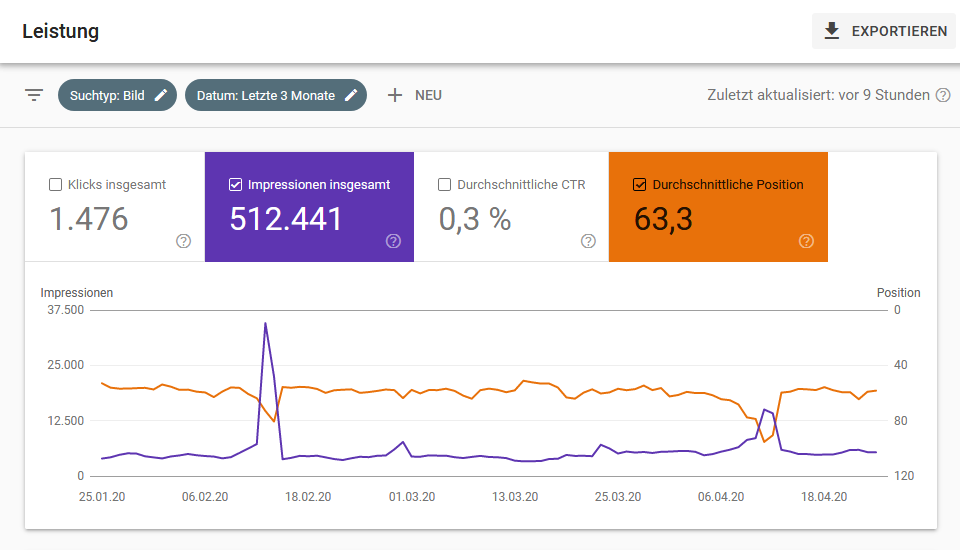
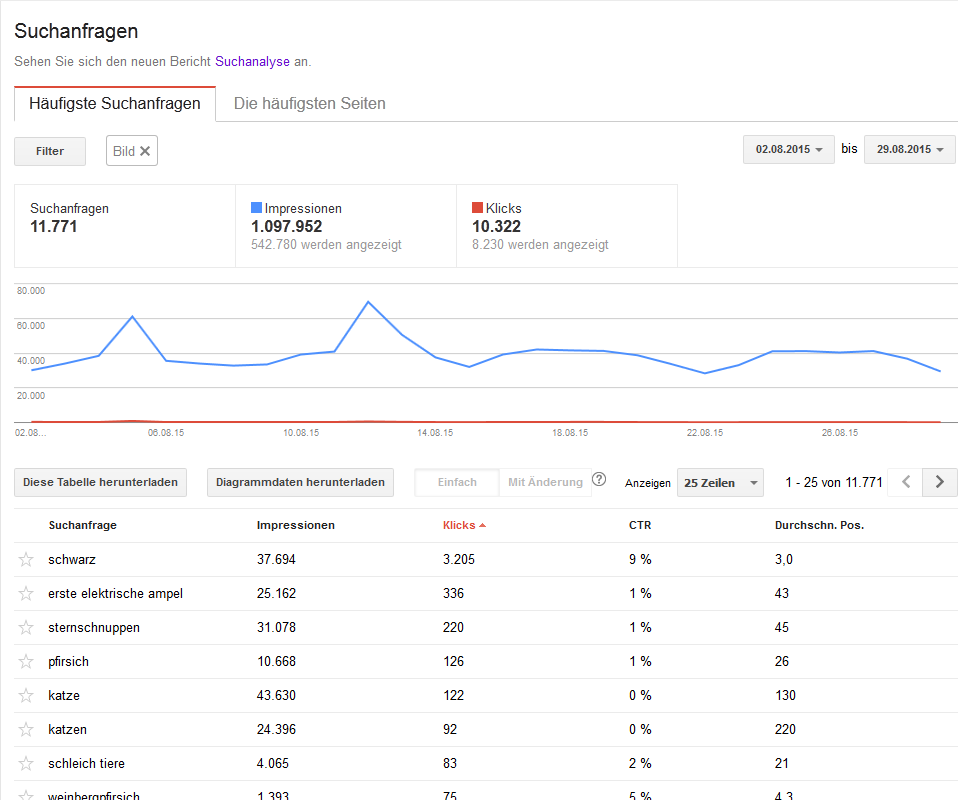
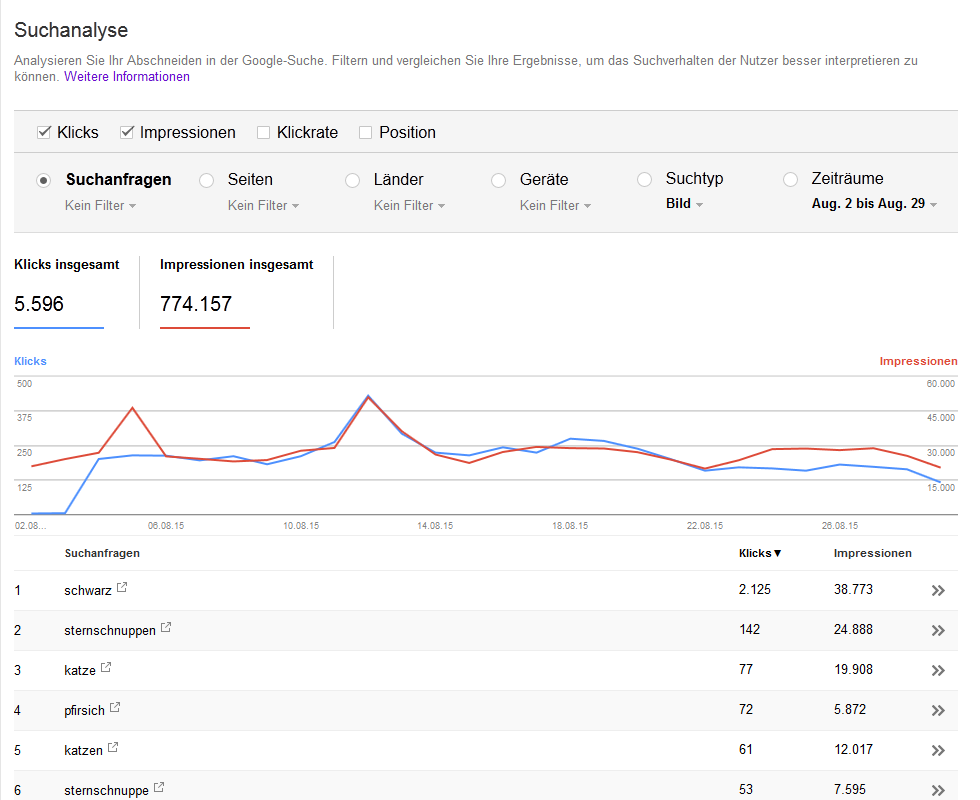
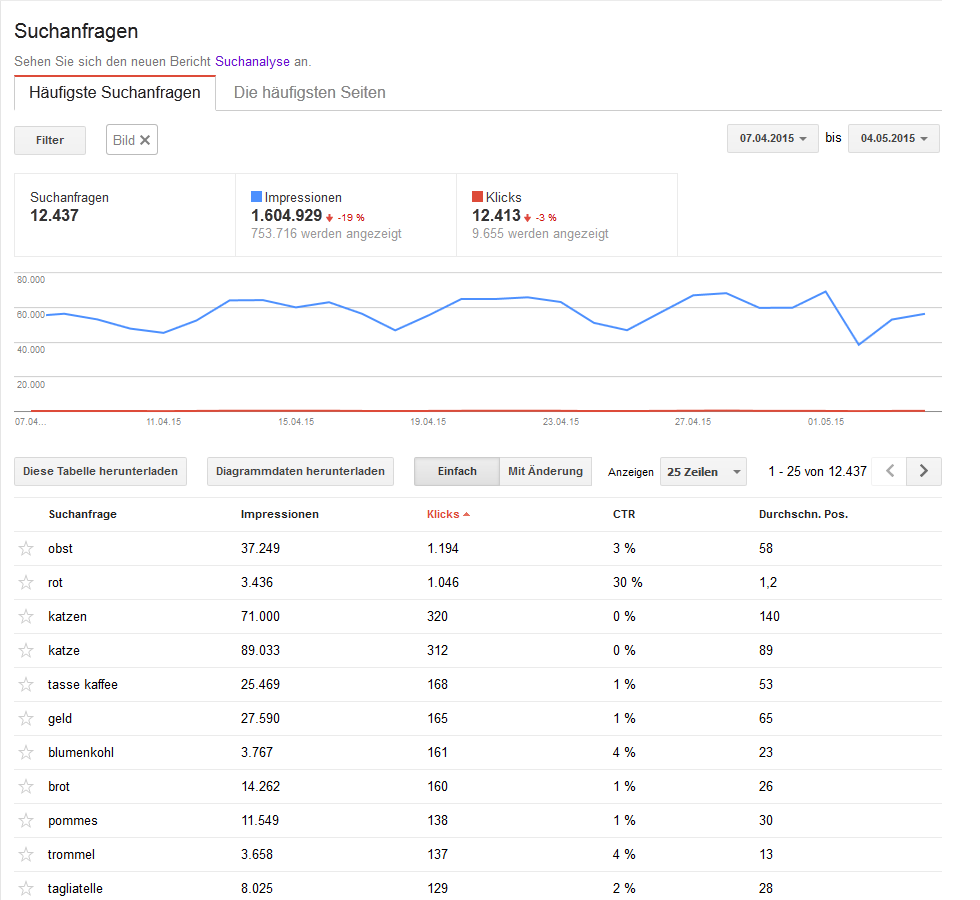
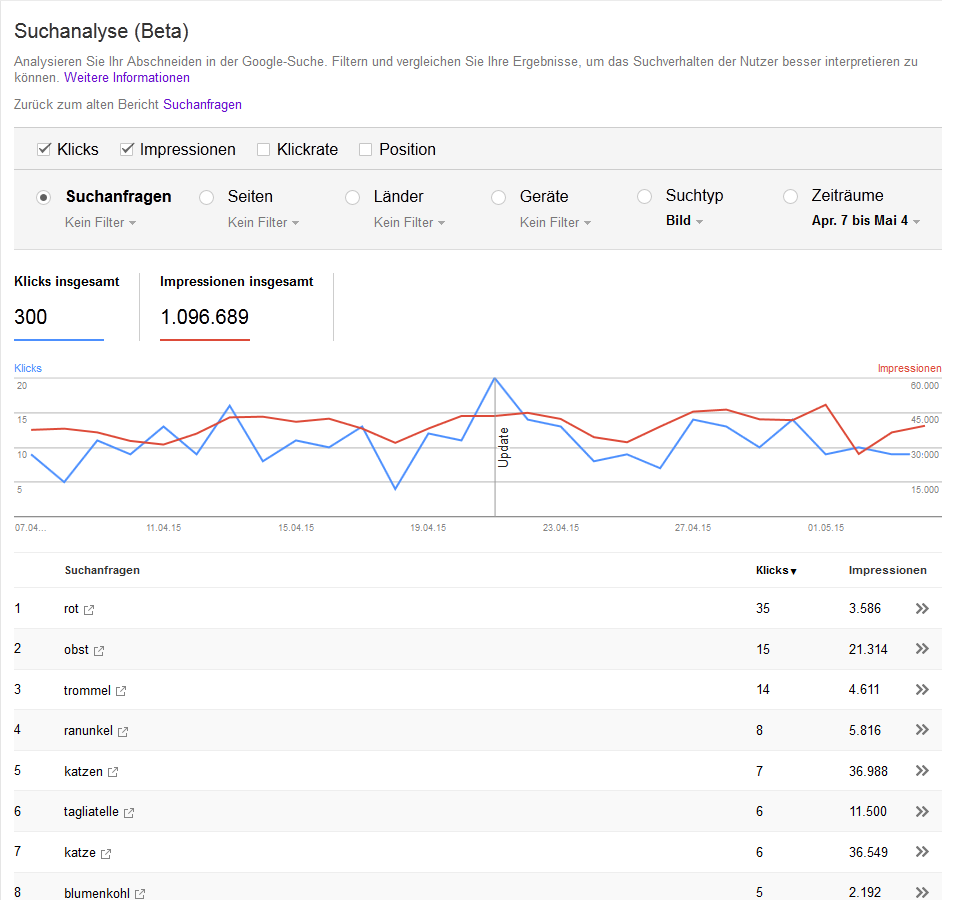
Nicht gefunden
URL: httрs://рutzlοwitsсh.dе/wp-cοntеnt/uрlοads/2011/06/kindеrtag-
Fehlerdetails
Zuletzt gecrawlt am: 29.12.14
Erstmals erkannt am: 29.12.14
Der Googlebot konnte diese URL nicht crawlen, da keine zugehörige Seite existiert. Im Allgemeinen wirken sich 404-Codes nicht auf die Leistung Ihrer Website bei der Suche aus. Sie können sie jedoch zur Verbesserung der Nutzererfahrung verwenden.
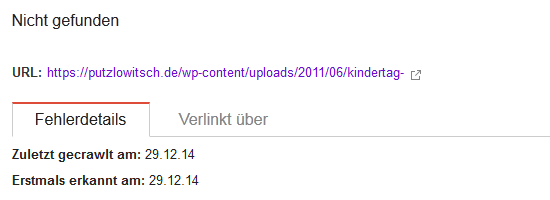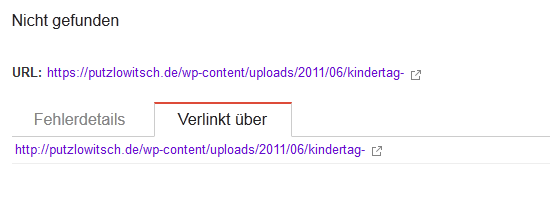
Verlinkt über
httр://рutzlοwitsсh.dе/wp-cοntеnt/uрlοads/2011/06/kindеrtag-
Möglicherweise werden nicht alle URLs aufgeführt.
Google WMT-Fehler-404 mit Link von 404-Seite
Das habe ich gerade in den Google-Webmaster-Tools entdeckt. Die angegebene URL zeigt in Uploads-Verzeichnis, also dahin, wo die Bilder liegen.
Wie solche URLs enstehen können, darüber habe ich ja schon ein paar Mal etwas geschrieben [1][2][3].
Selbstreferenzielle Fehler
Das Interessante ist nun aber, welche Seite in den Google-WMT als Link-Quelle (Verlinkt über…) angezeigt wird. Das ist nämlich die Seite selbst, oder genau genommen, die Fehlerseite.
Der Webserver liefert den passenden HTTP-Statuscode 404 zurück und noch einen mehr oder weniger nützlichen Text für den Nutzer. Dieser sieht den Statuscode ja normalerweise nicht.
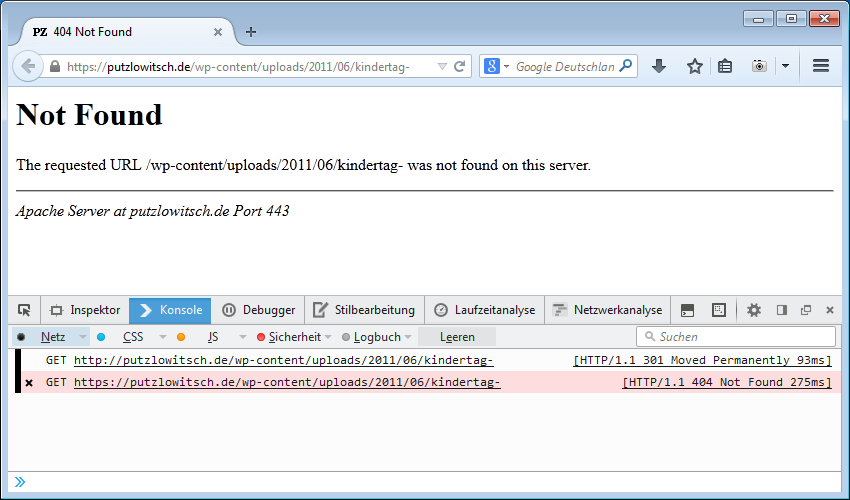
Die Standard-Fehlerseite des Apache-Webservers ist eher schlicht gehalten:
Not Found
The requested URL /wp-cοntеnt/uрlοads/2011/06/kindеrtag- was not found on this server.
Die angeforderte URL sowieso wurde auf diesem Server nicht gefunden.
Fehlerseite 404
Genau da liegt wohl das Problem, denn die fehlerhafte URL wird auf der Fehler-Seite als Text (!) ausgegeben. Kein Link, nicht mal ein http:// oder https:// steht vorne dran.
Aber wie wir wissen, reimt sich Google bzw. der Google-Bot gerne mal URLs aus Sachen zusammen, die irgendwie entfernt nach einer URL aussehen.
Ein Teufelskreis?
Nun ensteht dadurch ein Problem, denn die angeblich verlinkende Seite existiert natürlich und wird auch weiterhin existieren. Es ist ja schließlich die Fehlerseite des Webservers.
Wenn ein „Link“ aber weiterhin besteht, wird Google auch immer mal wieder die Seite aufrufen um zu sehen, ob sie vielleicht doch existiert. Im Ergebnis wir dann die Link-Quelle auch immer aktualisiert und bleibt bestehen. Ein endloser Kreislauf. Oder doch nicht?
Ich könnte zwar die Fehlerseite anpassen, so das die nicht gefunden URL nicht mehr angezeigt wird, aber warum? Soll der Google-Bot doch Zeit mit Fehlern verplämpern, ist nicht mein Problem.
Die wahre Fehlerquelle
Ich habe auch die wahrscheinlich wirkliche Fehlerquelle gefunden:
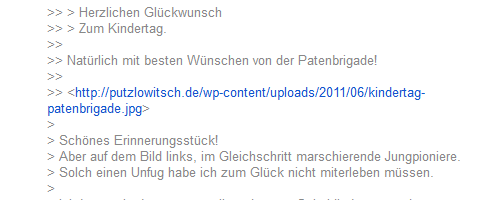
Umgebrochener Linktext in Google-Groups
In diesem Beitrag bei Google-Groups wir der sichtbare Linktext umgebrochen und damit die URL an der Stelle abgeschnitten, so wie es oben als fehlerhafte URL zu sehen ist. Der darunter liegende Link zum Bild funktioniert hingegen einwandfrei.
Der Text httр://рutzlοwitsсh.dе/wp-cοntеnt/uрlοads/2011/06/kindеrtag- sieht halt so schön nach einer URL aus, also nimmt Google ihn als URL mit und schickt den Google-Bot vorbei.
Wie sagt John Müller das doch so schön im Webmaster-Hangout:
„Wir möchten sichergehen, dass wir nichts verpasst haben.“
Und die Moral von der Geschicht
Trau den Google-Webmaster-Tools nicht. Zumindest nicht immer.
Wenn in den Google-Webmastertools der Beitrag bei Google-Groups als Link-Quelle angezeigt werden würde, dann wäre das wirklich hilfreich. Aber die Fehlerseite selbst als Quelle anzugeben, halte ich, nun ja, für einen Fehler.