Black Hat Sith / White Hat Jedi – SEO-Wettbewerb

Der schwarze Hut
Es gibt mal wieder einen SEO-Wettbewerb, gewissermaßen um das Sommerloch zu füllen. Der Start war am 27. Juli und er läuft noch bis zum 31. August. Der Gesamtwert der Preise von 40000 Euro wirkt recht spektakulär und auch der Ablauf und die Wertung der Teilnehmer klingen durchaus innovativ, was einen SEO-Wettbewerb angeht.
So wird nicht nur an einem Stichtag zu einer bestimmten Zeit das Ranking bei Google herangezogen. Vielmehr gibt es an fünf Tagen vor Ende des Wettbewerbs jeweils um 19 Uhr eine Punktevergabe für die Rankings von Platz 1 bis 40. Hier zählen aber nur „Text-Suchergebnisse“, also keine Bilder, Videos, News usw. Wer dann in der Summe die meisten Punkte hat, hat gewonnen. Einfach, aber durchaus mal etwas Neues bei einem SEO-Contest.
Und noch etwas ist anders als sonst, es gibt zwei Suchbegriffe, auf die optimiert werden soll: Black Hat Sith und/oder White Hat Jedi
Ausgerufen hat den SEO-Wettbewerb die Website CineStock, Anbieter für lizenzfreie Cinemagraphs, Videos, Bilder und Musik. Cinemagraphs bzw. Cinemagramme sind laut Wikipedia Standbilder, die eine oft kleine, sich wiederholende Bewegung enthalten. Sie erscheinen dem Betrachter eher als Bild statt als ein kurzes Video.
Onpage-SEO, nie davon gehört!
Wenn man sich die Seite zum Wettbewerb bei cinestock ansieht, wird klar, warum sie einen SEO-Wettbewerb ausgerufen haben. Denn die Seite benötigt dringen etwas Onpage-Optimierung. Eine vernünftige, technische Optimierung der Webseiten selbst ist die Basis jeder SEO-Maßnahme. Da können Inhalte und externe Links noch so gut sein, wenn die Seite lahm daherkommt, sind die Besucher schnell wieder weg und auch Google wird nicht mit Top-Rankings winken.
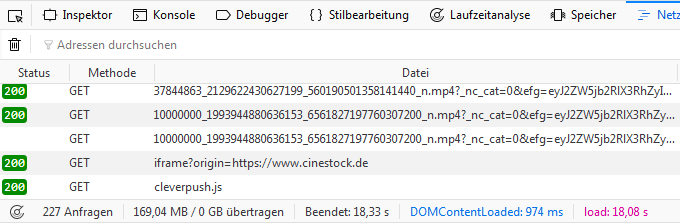
Cinestock – Netzwerkanalyse
Insgesamt 227 Abfragen laden mal eben knapp 170 MB herunter. Das dauert dann auch mit meiner DSL-100 Anbindung stolze 18 Sekunden.
So werden die Logos der 36 Sponsoren und 26 Medienpartnern als einzelne JPEG-Bilder eingebunden.
Cinestock – Medienpartner Logos
Den Vogel schießt hier das 193×50 Pixel „große“ Logo von „SEO-Trainee“ ab, das als JPEG mal eben mit 650 kB zu Buche schlägt. Als PNG dürfte es etwa 10 kB groß sein.
Generell ist für Logos und Grafiken das PNG-Format besser geeignet und bei einer Vielzahl von kleinen Bildchen sollte man auch über Techniken wie CSS-Sprites oder Ähnliches nachdenken.
Aber gut, das PNG-Format kommt dann doch noch zum Einsatz. Allerdings hier nun für Bilder, die eher Foto-Charakter haben und für die daher besser das JPEG-Format geeignet ist.
Cinestock – Bilder (als PNG)
Am Ende der Seite findet man „Content für deine Seite“, eine Liste mit 20 Fotos der Größe 1920×1080 Pixel im PNG-Format und weiteren 35 Cinemagramme mit einer Breite von 650 Pixel als animierte GIF-Dateien. Gut, für die Cinemagramme ist wegen der Animation das GIF-Format die einzige Option. Aber für die Fotos wäre man mit JPEG-Bildern besser gefahren, das Bild „Black Hat Pokal 3“ ist als PNG über 3 MB groß, als JPEG dürfte es bei noch guter Qualität um 300 kB groß sein.
Aber unabhängig von der Eignung oder Nichteignung des Bildformates ist es keine gute Idee, 55 recht große Bilder auf einer Seite direkt als Bild in der Originalgröße einzubinden. Hier hätte es eine Galerie mit kleinen Vorschaubildern, die auf das Originalbild verlinken, auch getan.
Und was ist mit Facebook?
Allein 61 externe Requests gehen zum Facebook-CDN (fbcdn.net), davon 11 CSS, 29 JS und 15 mp4-Videos. Was für Videos eigentlich? Ganz oben am Anfang der Seite ist ein FB-Video als Erklärvideo eingebunden, aber was ist mit den 14 anderen?
Viele, externe Ressourcen sind der Seitengeschwindigkeit auch nicht gerade zuträglich.
SEO fängt mit Onpage an
Liebe Betreiber von CineStock, bevor Ihr einen SEO-Wettbewerb startet, solltet Ihr erst einmal die SEO-Hausaufgaben machen. Sonst verpuffen die positiven Effekte des Wettbewerbs ganz schnell unter der ächzenden Last einer lahmen Webseite!