
Wikipedia bei Google ganz vorn
Daß die Wikipedia bei vielen Google-Suchanfragen auf Platz 1 oder 2 zu finden ist, dürfte nichts Neues sein. Bei den Bildern in der Google-Bildersuche zeigte sich mir dieser Trend aber erstmalig Anfang/Mitte Juni dieses Jahres. Nach den Bildern von damals sind in den letzten Tagen weitere Bilder von meiner Beobachtungsliste hinzu gekommen. Hier ein paar Beispiele.
Katze
-

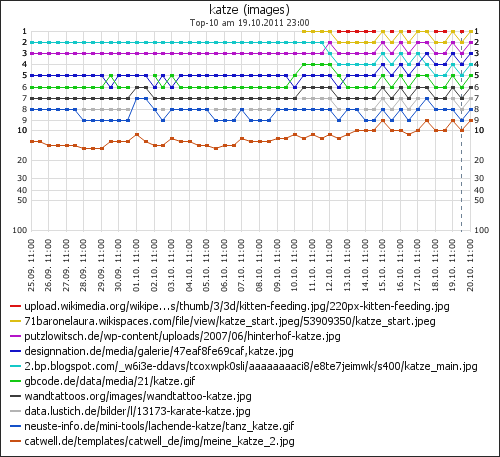
- Wikipedia Katze Diagramm
-

- Google-Bildersuche: Katze Wikipedia
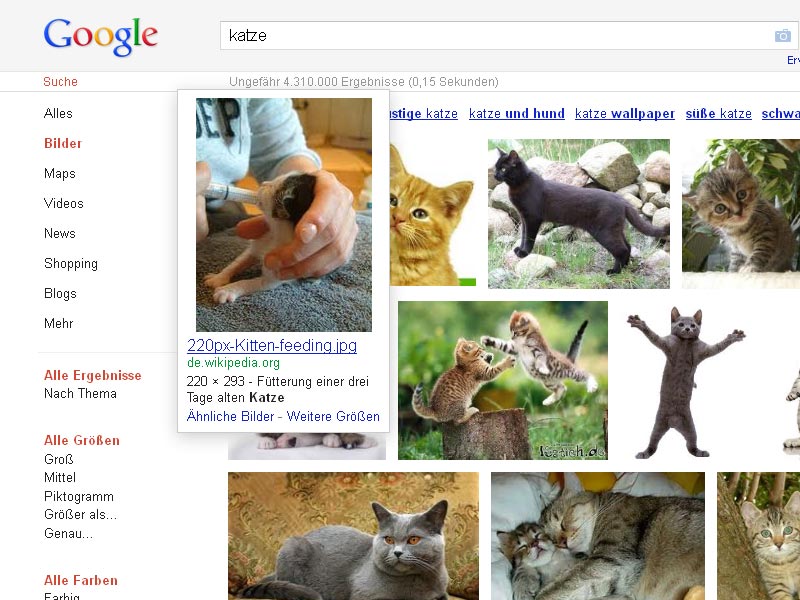
Zuerst war es mir beim Suchbegriff Katze aufgefallen. Da tauchte am 12. Oktober quasi aus dem Nichts ein Katzenbild direkt auf Position 1 auf (Diagramm rote Linie, wikimedia.org). Im Moment ist sich Google noch nicht ganz schlüssig, ob das Bild da bleiben soll, mal ist es da, mal nicht. Aber ich denke, es wird sich demnächst dort festsetzen.
Äpfel
-
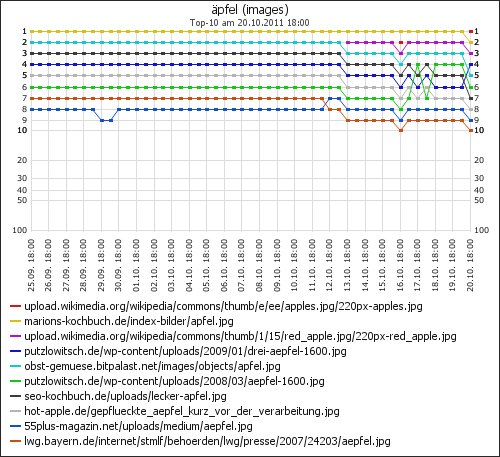
- Wikipedia Äpfel Diagramm
-
- Google-Bildersuche: Äpfel Wikipedia
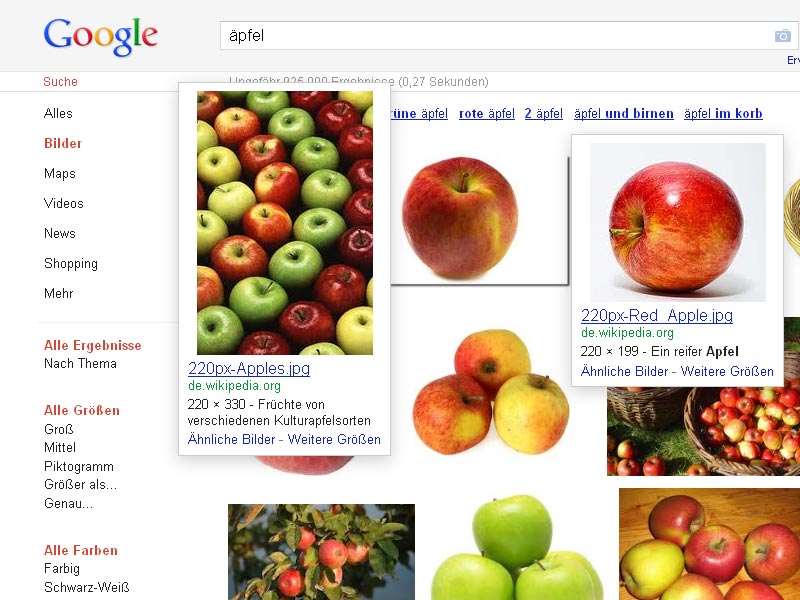
Am 13. Oktober war ganz neu auf Platz 2 der Bildersuche ein Wikipedia-Apfel zu sehen (violette Linie, wikimedia.org). Später ist dann noch ein zweites Bild dazu gekommen (rote Punkte). Derzeit mischen also zwei Wikipedia-Äpfel-Bilder ganz vorn mit, einer auf dem ersten und einer auf dem dritten Platz.
Hut
-
- Wikipedia Hut Diagramm
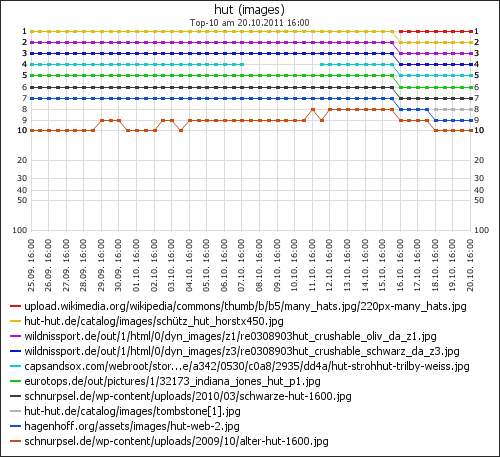
-
- Google-Bildersuche: Hut Wikipedia
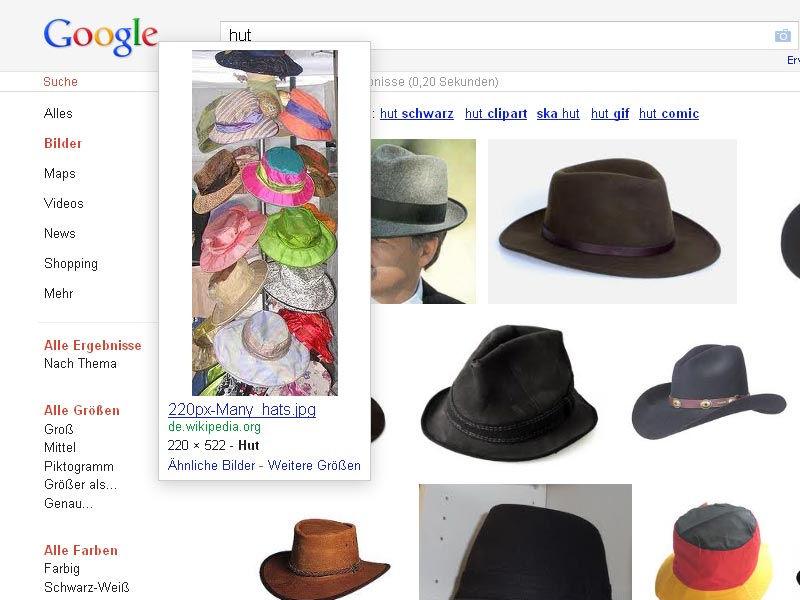
Seit dem 16. Oktober belegt auch ein Wikipedia-Bild zum Suchbegriff Hut den ersten Platz in der Bildersuche (rote Linie, wikimedia.org). Das Bild zeigt keinen einzelnen Hut, sondern gleich viele bunte Hüte.
Mona Lisa
 Die Mona Lisa habe ich erst seit kurzem auf dem Monitor in der Beobachtungsliste, deshalb gib es dafür auch noch kein wirklich aussagekräftiges Rankingdiagramm.
Die Mona Lisa habe ich erst seit kurzem auf dem Monitor in der Beobachtungsliste, deshalb gib es dafür auch noch kein wirklich aussagekräftiges Rankingdiagramm.
Allerding werfe ich hin und wieder schon mal einen Blick auf die Mona Lisa Bildersuchergebnisse.
Das passiert spätestens immer dann, wenn der Künstler Martin Mißfeldt sein Lieblingsbeispiel Mona Lisa in einem seiner Artikel beim TagSEOBlog ins Spiel bringt. :-)
Das jetzt auf Platz 1 liegende Bild habe ich dort auf einem Screenshot oder bei der eigenen Suche noch nie gesehen. Es wäre mir allein schon deshalb aufgefallen, weil es gar nicht Leonardo da Vincis berühmte Mona Lisa oder eine Abwandlung davon zeigt. Das Wikipedia-Bild ist Camille Corots „Frau mit einer Perle“, welches vorübergehend den Platz der Mona Lisa im Louvre einnahm, als das Original gestohlen worden war.
Google wertet Wikipedia in der Bildersuche auf
Wenn Bilder plötzlich wie aus dem Nichts (von Plätzen jenseits der 100) auf dem ersten oder zweiten Platz der Bildersuche landen, sind das aus meiner Sicht keine „normalen“ Rankingverschiebungen.
Es kann natürlich sein, das die Wikipedia gerade besonders auf Bilder optimiert. Ich denke aber, Google hat mal wieder an den Rankingschrauben gedreht und irgendwelche Gewichtungen verändert. Vielleicht gib es ja sowas wie Panda auch für die Bildersuche, wer weiß…







{kind=link}
{kind=link}