Der Inhalt
Das Problem
Google-Bildersuche mit Originalbild
In der „neuen“ Google-Bildersuche wird beim Klick auf ein Ergebnis das Bild direkt in der Bildersuche in voller Auflösung geladen und angezeigt. Das dürfte viele Nutzer davon abhalten, die Ursprungsseite zu besuchen.
Um den Benutzer zu motivieren, dennoch die Originalseite zu besuchen, könnte man dem Nutzer innerhalb der Google-Bildersuche eine Bild in schlechter Qualität (unscharf/verpixel) mit einem zusätzlichen Hinweistext anzuzeigen. Das findet aber Google nicht so toll, es wird möglicherweise als Bilder-Cloaking gewertet. Das könnte wiederum eine manuellen Maßnahmen zur Folge haben.
Die Lösung
Seit einiger Zeit bietet Google im oben verlinkten Hinweis zum Bilder-Cloaking eine „legale“ Lösung für das Problem an
Bild in den Suchergebnissen minimieren oder blockieren
- Sie können verhindern, dass das Bild auf der Google-Suchergebnisseite in Originalgröße angezeigt wird, indem Sie das Inline-Linking deaktivieren.
- …
So deaktivieren Sie das Inline-Linking:
- Wenn Ihr Bild angefordert wird, prüfen Sie den HTTP-Verweis-URL-Header in der Anfrage.
- Falls die Anfrage von einer Google-Domain stammt, antworten Sie entweder mit HTTP 200 oder mit HTTP 204, „keine Inhalte“.
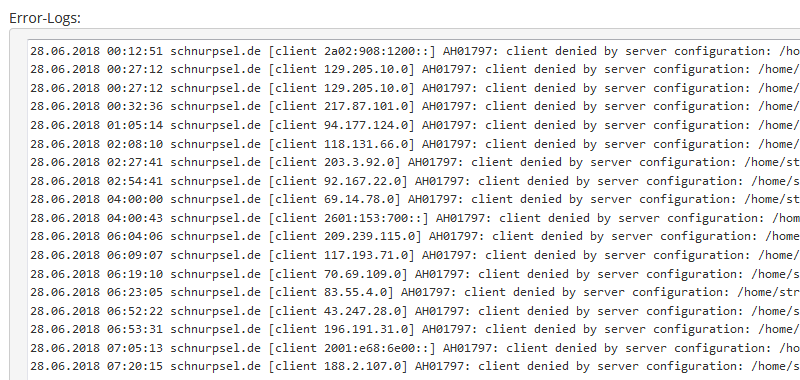
Google crawlt Ihre Seite und sieht das Bild weiterhin. In den Suchergebnissen wird jedoch nur das Miniaturbild angezeigt, das während des Crawlings generiert wurde. Die Funktion kann jederzeit deaktiviert werden. Die Bilder einer Website müssen dazu nicht noch einmal verarbeitet werden. Diese Methode wird nicht als Bild-Cloaking betrachtet und hat auch keine manuellen Maßnahmen zur Folge.
Wobei hier mit „Inline-Linking“ das gemeint ist, was allgemein als „Hotlinking“ bekannt ist. Und so ähnlich wie die berühmte Hotlink-Sperre funktioniert auch die Google-Bilder-Sperre.
Die Umsetzung
Als technische Basis setze ich einen Apache-Server mit den aktiven Modulen mod_rewrite, mod_headers und mod_setenvif voraus. Wobei das Modul mod_setenvif nicht zwingend erforderlich ist, es macht die Sache aber übersichtlicher:
<IFModule mod_headers.c>
Header always set Cache-Control "no-cache, no-store, must-revalidate" env=NO_CACHE
</IfModule>
<IfModule mod_setenvif.c>
SetEnvIf Accept "text/html" REQ_HTML=1
SetEnvIf Referer "^https?://(([^\.]+?\.)?([^\.]+?\.)?[^\.]+?)/" DOM_REFERER=$1
</IfModule>
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{ENV:REQ_HTML} !1
RewriteCond %{REQUEST_FILENAME} -f
RewriteRule \.(jpg|gif|png)$ - [NC,C]
RewriteCond %{ENV:DOM_REFERER} google\.(com|de|at|ch)$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} bing\.com$ [NC]
RewriteRule .* /status-204.sta
RewriteRule ^status-204.sta$ - [R=204,E=NO_CACHE:1,L]
</IfModule>Die Technik
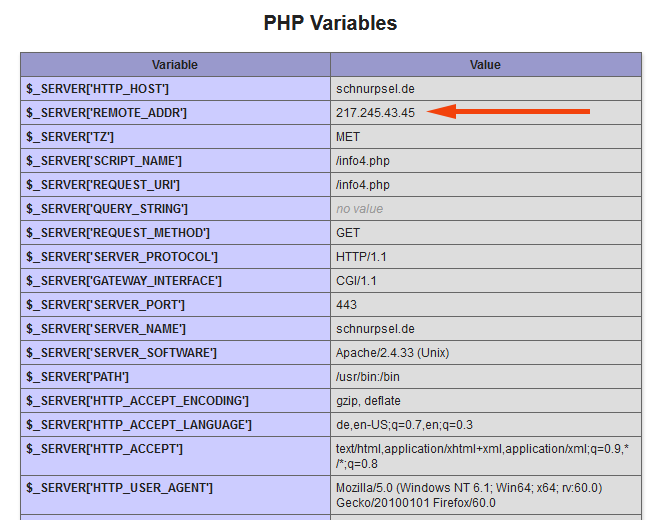
Zur Unterscheidung von Bildaufruf (img src=…) und Link verwende ich den Wert von „Accept“ im HTTP-Request-Header. Nach meiner Beobachtung enthält dieses Header-Feld bei Bild-Aufrufen nicht den Typ „text/html“, beim Aufruf von Links, auch zu Bildern, aber schon. Wenn also „text/html“ im Accept-Header zu finden ist, dürfte es sich um den Link zum Bild und nicht um das Laden des Bildes in der Google-Ansicht handeln.
Die Umgebung
<IfModule mod_setenvif.c> SetEnvIf Accept "text/html" REQ_HTML=1 SetEnvIf Referer "^https?://(([^\.]+?\.)?([^\.]+?\.)?[^\.]+?)/" DOM_REFERER=$1 </IfModule>
Den Accept-Header werte ich in einer SetEnvIf Anweisung aus und setze eine entsprechende Variable, die ich später in den Rewrite-Regeln auswerten kann. Zudem extrahiere ich in dem Block den Domain-Namen aus dem Referer, da ich diesen auch in anderen Rewrite-Regeln benötige.
Das Bild
RewriteCond %{ENV:REQ_HTML} !1
RewriteCond %{REQUEST_FILENAME} -f
RewriteRule \.(jpg|png|gif|webp)$ - [NC,C]
Mit den Rewrite-Regeln prüfe ich zunächst, ob es ein Bildaufruf (img src=…) ist, die Existenz der Datei (sonst soll die normale 404-Verarbeitung greifen) und über die Datei-Erweiterung, ob ein Bild aufgerufen wird. Falls nicht, wir der nächste Block der Rewrite-Regeln gar nicht erst ausgeführt.
Die Referrer
RewriteCond %{ENV:DOM_REFERER} google\.(com|de|at|ch)$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} bing\.com$ [NC]
RewriteRule .* /status-204.sta
Im zweiten Block wird eine Liste von Referrer-Domains abgearbeitet, für die die Weiterleitung erfolgen soll. In dem Fall sind es die vier Google-Domains, von denen die meisten meiner Besucher kommen und bing.com (ja, das funktioniert auch für Bing :-). Die Abfrage nach dem Referer kann man natürlich auch anders gestalten. Das hängt halt davon ab, was man damit erreichen will.
Die anschließende RewriteRule erzeugt eine internes Rewrite zur einer leeren Dummy-Datei (status-204.sta), die aber existieren muß. Das ist erforderlich, um den Cache-Header korrekt setzen zu können. Wenn der Browser die Daten cachen würde, wäre das Bild möglicherweise auch nicht auf der Webseite zu sehen.
Die Regel
RewriteRule ^status-204.sta$ - [R=204,E=NO_CACHE:1,L]
Diese einzelne Regel setzt letzendlich den HTTP-Statuscode „204 No Content“ und triggert die Ausgabe des NoCache-Headers.
Der Cache
<IFModule mod_headers.c> Header always set Cache-Control "no-cache, no-store, must-revalidate" env=NO_CACHE </IfModule>
Außerdem setze ich einen Wert (NO_CACHE), mit dem am Ende geprüft wird, ob das Caching deaktiviert werden soll. Der Block mod_headers steht zwar am Anfang, der Webserver führt diese Anweisungen aber erst ganz zum Schluß aus, kurz bevor die Antwort an den Client gesendet wir. Damit wird das Caching des von Google direkt geladenen Bildes verhindert.
Das Ergebnis
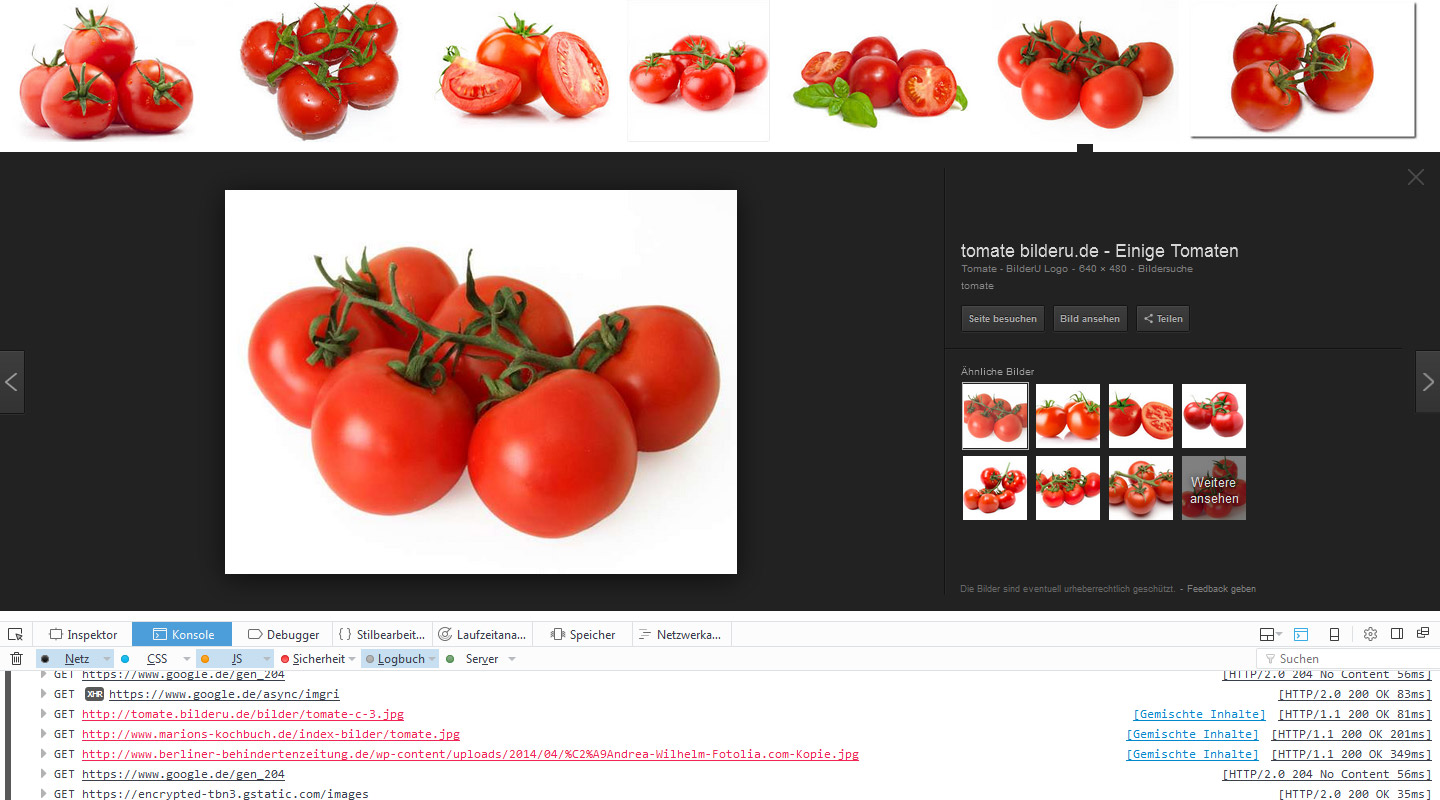
Im Ergebnis lädt Google unser Bild nicht in der ausgklappten Ansicht innerhalb der Bildersuche. Stattdessen wird das vergrößerte Thumbnail des Bildes angezeigt, das Google als Vorschaubild gespeichert hat und das in der Übersicht zu sehen ist.
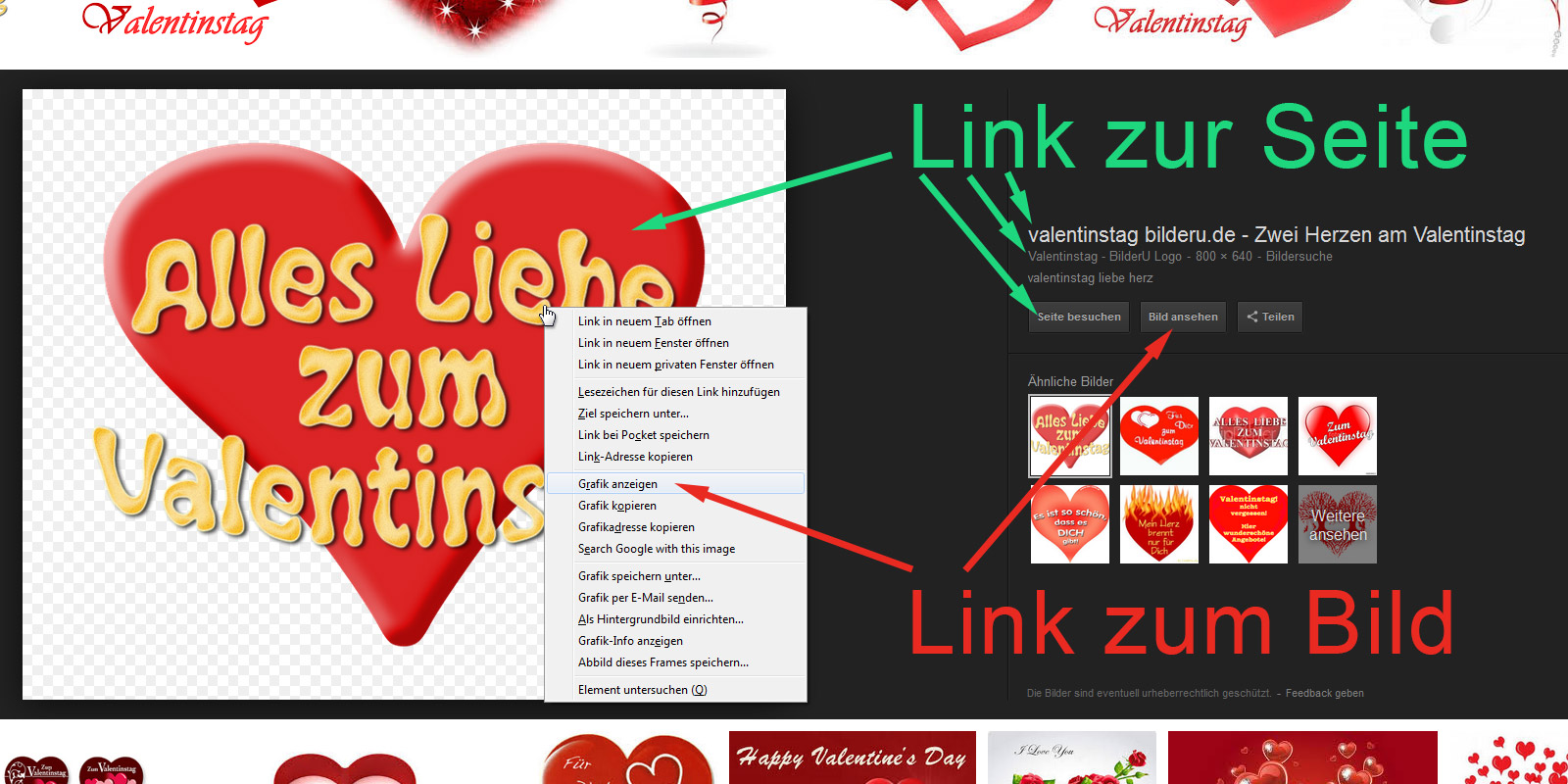
Das Bild ist entsprechend unscharf und verpixelt. Der Nutzer kann unser Bild auch nicht einfach per Rechtsklick und „Grafik anzeigen“ oder „Grafik speichern unter…“ ansehen oder speichern- Wenn er das Originalbild sehen oder speichern will, muß er also unsere Webseite besuchen und schon haben wir wieder einen Besucher mehr. :-)