Wikipedia-Bilder in der Universal Search
Daß die Wikipedia bei vielen Google-Suchanfragen auf Platz 1 oder 2 zu finden ist, daran hat man sich mittlerweile gewöhnt. In der Google-Bildersuche und bei den Bilder-Einblendungen in der organischen Suche (Universal Search) ist das noch nicht lange so. Da meistens die ersten Ergebnisse der Bildersuche auch in der Universal Search erscheinen, waren da natürlich auch die Wikimedia-Bilder vertreten, die es in letzter Zeit an die Spitze der Bildersuche geschafft hatten.
Seit ein paar Tagen habe ich nun einen neuen Trend beobachtet.
Universal Search bevorzugt Wikipedia-Bilder
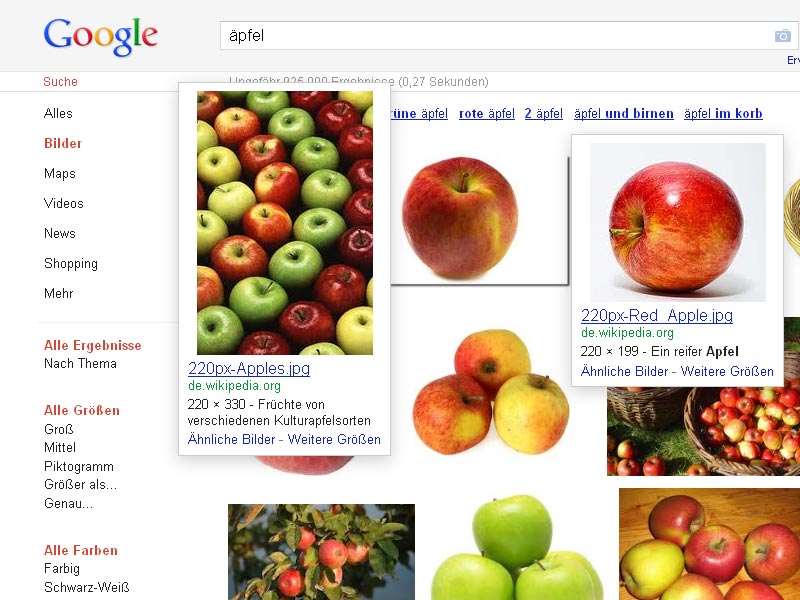
Bei mehreren Suchbegriffen passiert es nun, daß in der Universalsearch ein oder zwei Wikipedia-Bilder noch vor den „regulären“ Bildersuche-Treffern platziert werden. Diese Bilder sind in der Google Bildersuche selbst nicht zu finden. Hier ein paar Beispiele:
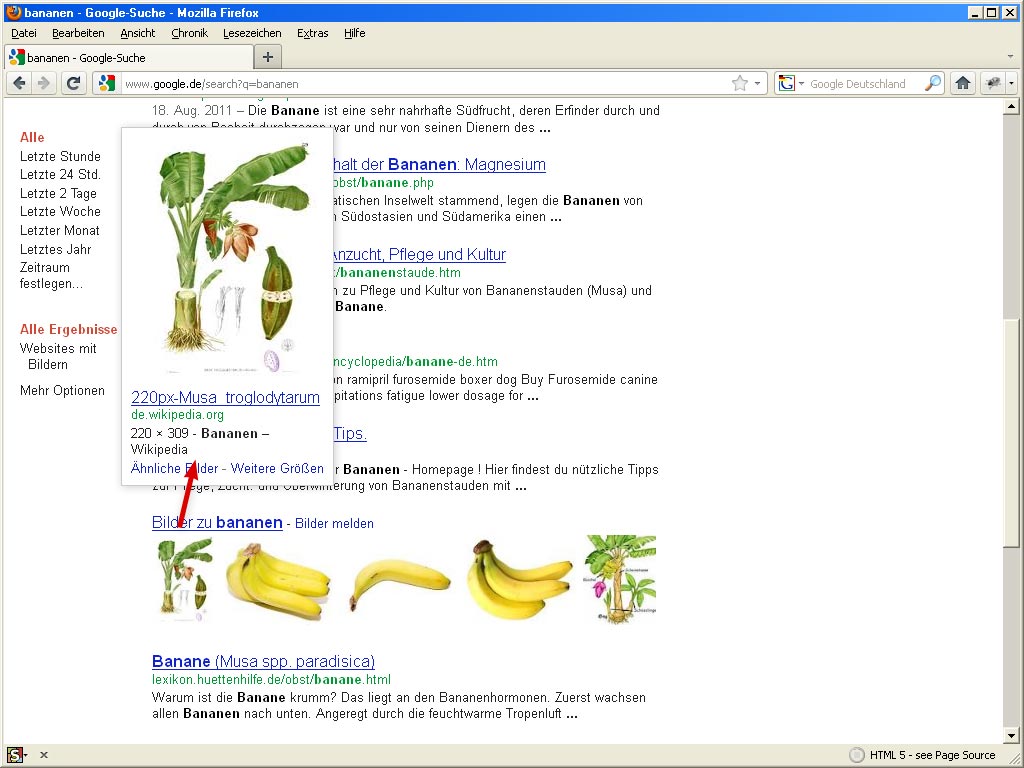
Bananen
-

-
Google Bildersuche Bananen
-
-
Googlesuche Bananen
Die ersten vier Bilder aus der Bildersuche findet man in der organischen Suche. Davor wurde aber ein Wikipedia-Bild gesetzt.
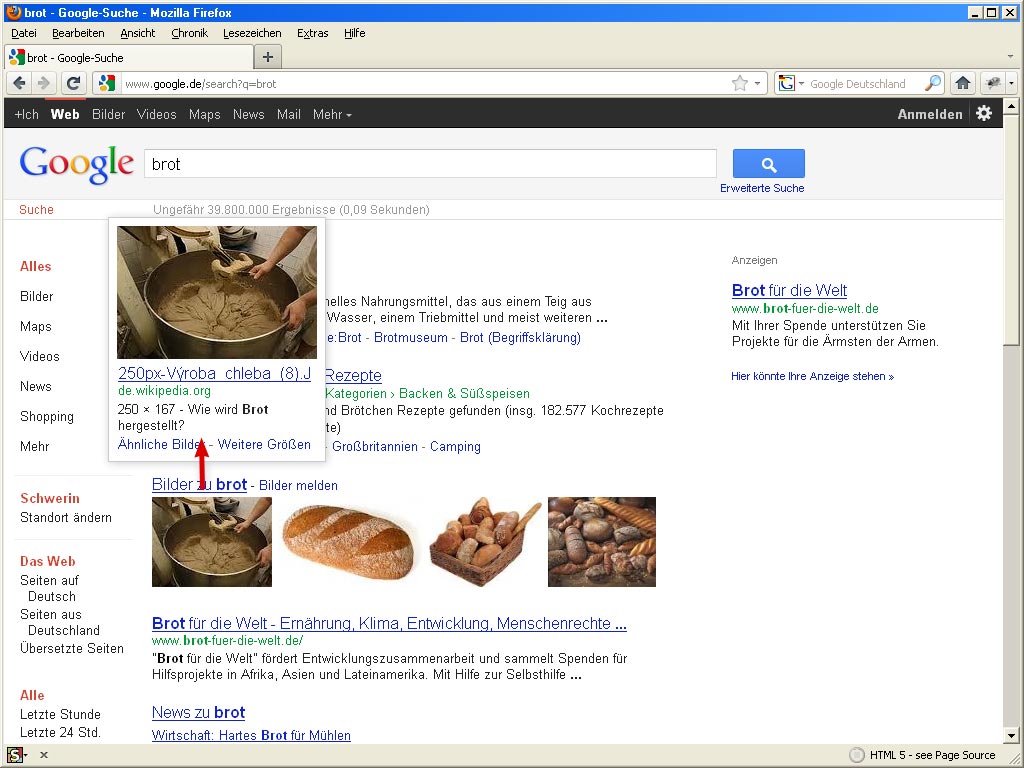
Brot
-
-
Google Bildersuche Brot
-
-
Googlesuche Brot
Die ersten drei Bilder aus der Bildersuche haben es in die „normale“ Suche geschafft. Das erste Bild kommt wieder von der Wikipedia und zeigt gar kein Brot, sondern eine Bottich mit Brotteig.
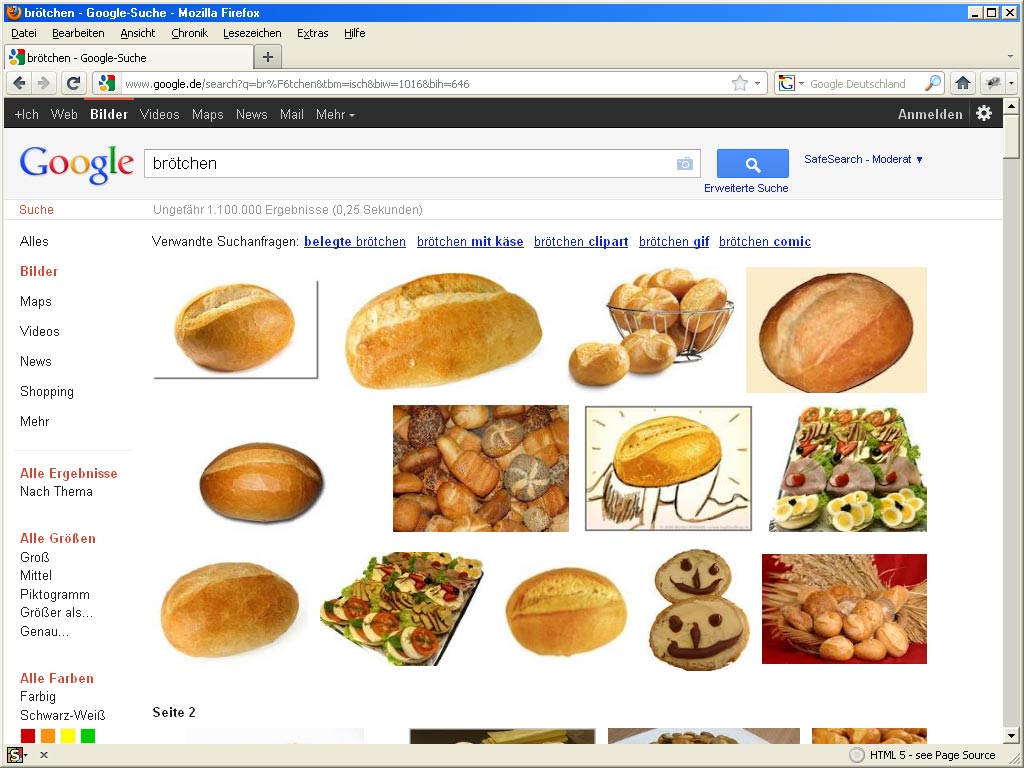
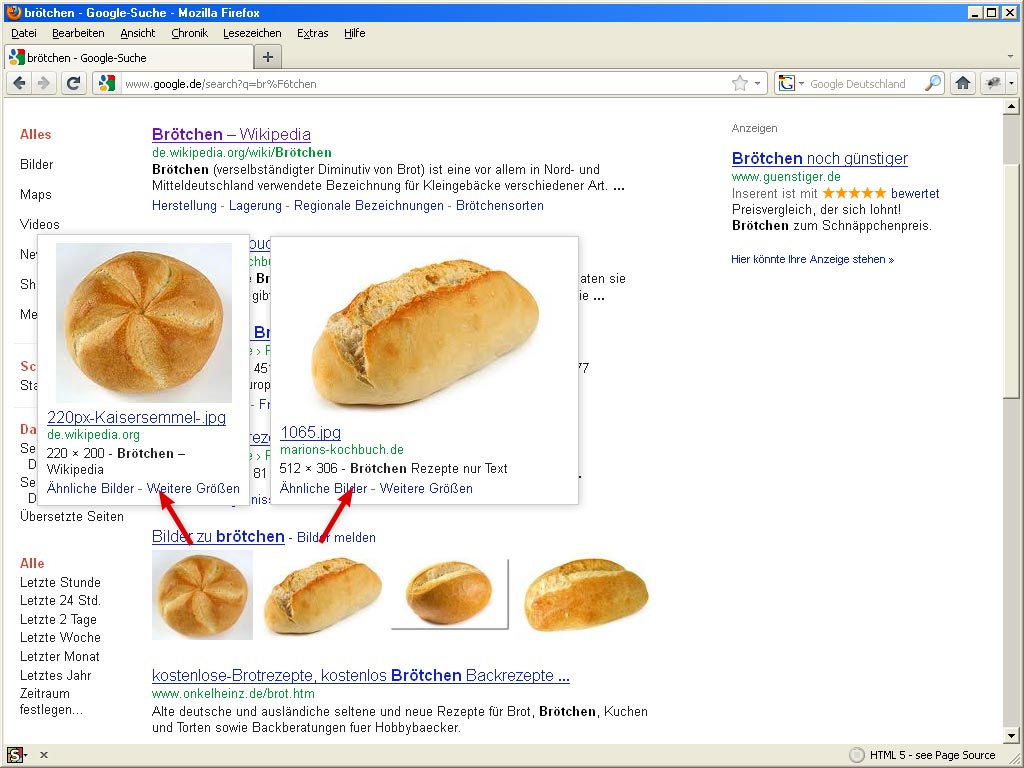
Brötchen
-
-
Google Bildersuche Brötchen
-
-
Googlesuche Brötchen
Vom Brot kommt man schnell zum Brötchen. :-) Hier wurde nun die Regel durchbrochen. Vor den zwei Bildern aus der Bildersuche kommt zunächst ein Wikipedia-Bild und dann noch ein Kochbuch-Bild. Das dürfte in etwa das gewesen sein, was Martin Mißfeldt hier gesehen hatte.
Nun kommen noch ein paar „handfestere“ Sachen als Obst und Backwaren.
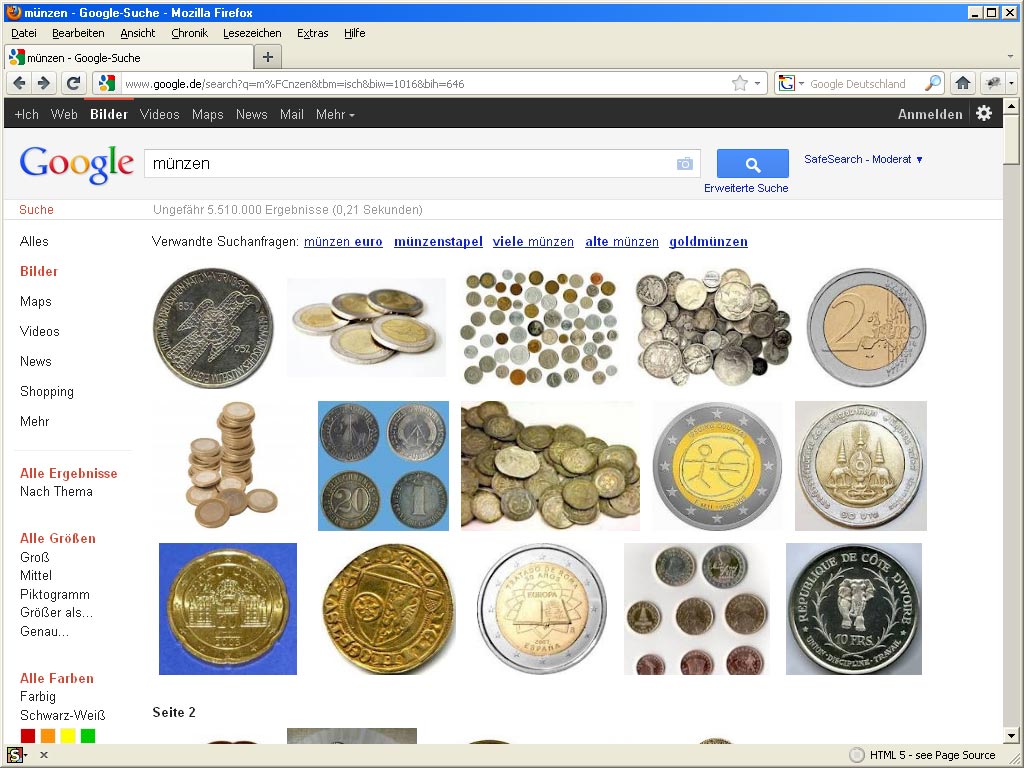
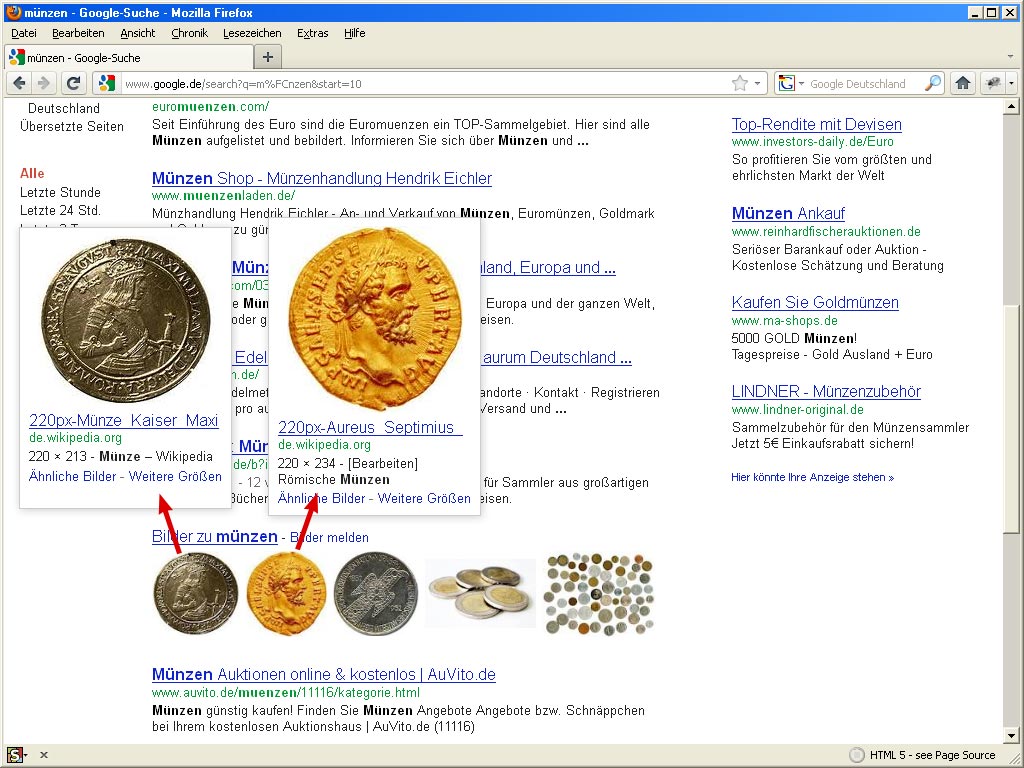
Münzen
-
-
Google Bildersuche Münzen
-
-
Googlesuche Münzen
Bei den Münzen liegen vor den Ergebnissen aus der Bildersuche gleich zwei Wikipedia-Bilder.
Weil es stramm auf die Adventszeit und Weihnachten zugeht, gibt es als letztes Beispiel die Kerzen.
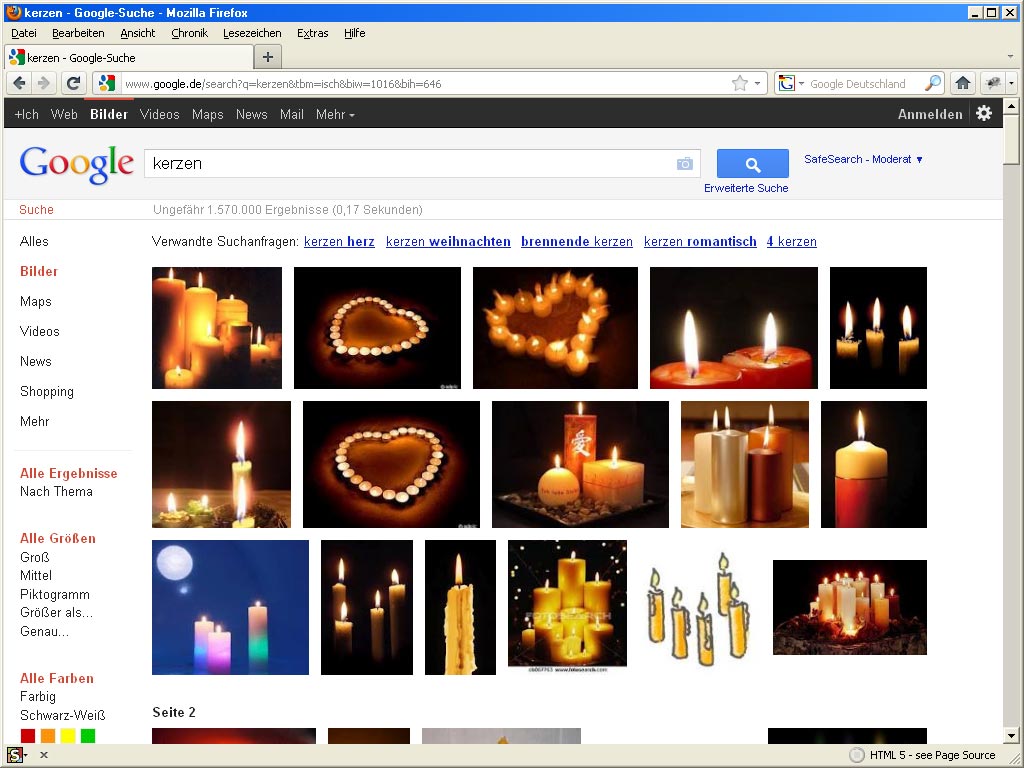
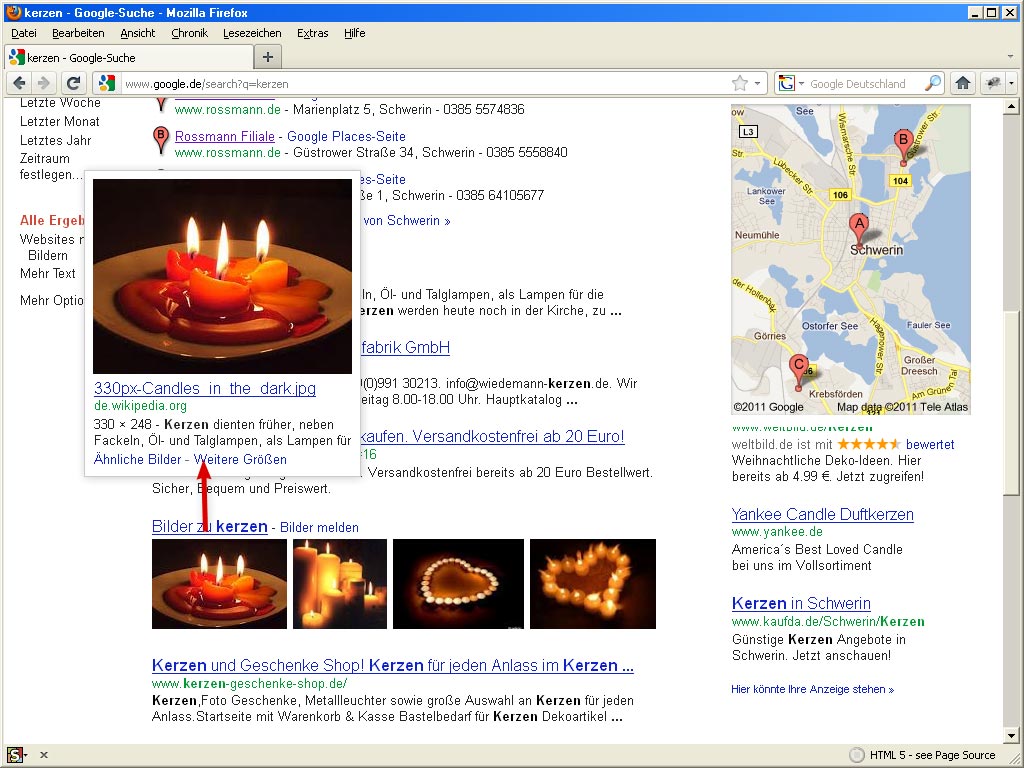
Kerzen
-
-
-
Googlesuche Kerzen
Hier haben wir dann wieder den „Normalfall“, ein Wikipediabild steht vor den Treffren der Bildersuche.
Richtig oder falsch
Ich sehe diese neue Google-Taktik eher zwiespältig. Zum einen bin ich als Bildermacher direkt davon betroffen, weil es meine Bilder nun deutlich schwerer haben in die Universal Search zu kommen, als vorher. Andererseit, warum soll es den Bildern besser ergehen als den Textsuchergebnissen?
Auch aus Benutzersicht ist es einerseits positiv, daß die Wikipedia-Bilder mehr in den Fokus rücken, ergeben sich doch bei deren Verwendung praktisch keine Risiken bezüglich der Nutzungsrechte. Was es mit anderen Bildern für Probleme geben kann, ist seit der Sache mit den Kochbuch-Brötchen ja hinlänglich bekannt.
Allerding ist die inhaltliche wie auch fotografische Qualität der Wikipedia-Bilder bisweilen, nun ja, nicht wirklich gut. Die Bildauswahl dürfte manchmal vermutlich auch nicht den Erwartungen des Suchenden entsprechen.
Wenn ich in der Bildersuche nach Brot suche, erwarte ich Bilder von Brot zu finden und nicht unbedingt einen Topf mit einer undefinierbaren, braunen Pampe. Es gibt noch ein paar weitere Beispiel, wo ich das Wikipedia-Bild thematisch nicht ganz so passend finde.
Wie geht es weiter?
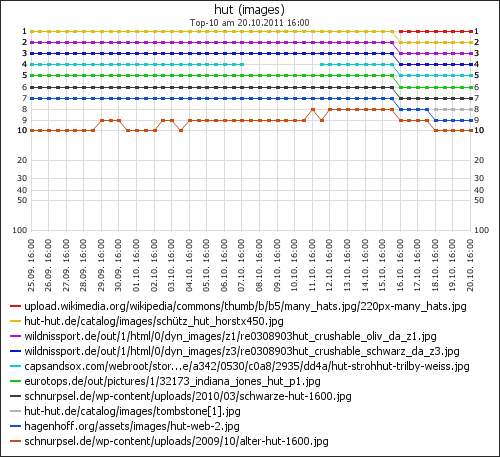
Zunächst muß man abwarten, wie sich alles entwickelt. Der Bildersuche-Updateprozeß scheint noch nicht abgeschlossen zu sein. Es bleibt spannend.


 Erfreulich für mich ist natürlich, daß mein Brötchen mit ö relativ stabil auf Platz 2 zu finden ist, zwischenzeitlich am 24.10. sogar auf dem ersten Platz.
Erfreulich für mich ist natürlich, daß mein Brötchen mit ö relativ stabil auf Platz 2 zu finden ist, zwischenzeitlich am 24.10. sogar auf dem ersten Platz. am 27.10.2011") Das Gerangel um das Spitzen-Brötchen geht weiter. Möglicherweise wird nicht einer der Brötchen-Ritter gegen das schwarze Brötchen gewinnen, sondern die Wikiritteria.
Das Gerangel um das Spitzen-Brötchen geht weiter. Möglicherweise wird nicht einer der Brötchen-Ritter gegen das schwarze Brötchen gewinnen, sondern die Wikiritteria.



{kind=link}