

Schnurpsel wünscht allen Lesern
ein frohes Osterfest.
Hier gibts weitere Bilder zu Ostern.
Hier gibts weitere Bilder zu Ostern.



Nach der Campixx 2011 und 2012 war das in diesem Jahr nun meine dritte SEO-Campixx am schönen Müggelsee in Berlin Köpenick. Eine Reise nach Köpenick ist für mich auch immer eine Rückkehr in meine alte Heimat, denn hier habe ich viele Jahre gelebt.
Dieses Jahr war es so kalt wie noch nie zuvor bei einer SEO-Campixx (zumindest bei denen ich war). Eisige -8 °C zeigte das Thermometer am Samstag früh, als ich mich aus meinem Köpenicker Quartier auf den Weg zum „Hotel am Müggelsee“ machte. Aber bange machen ist nicht, also auf geht’s.



Nach der Anmeldung ging es direkt zur Eröffnungveranstaltung im großen Saal. Campüxx-Chef Marco Janck kam als Geist daher, genau wie bereits im Campixx-Video. Das Video wurde auch am Anfang zur Einstimmung gezeigt. Auch wenn es nicht unbedingt meine Musikrichtung ist, da habe ich aber auch schon schlechtere Sachen gesehen.
Nach gemeinsamem Trommeln und Comedy-Redner war der Kulturteil diesmal ein Luftballon-Show, fast theatralisch könnte man sagen. Mit sieben Teilnehmern aus dem Publikum wurde eine fiktive Szene aus „Star Wars“ nachgestellt. War recht lustig anzusehen. Ich weiß schon, warum ich mich bei solchen Veranstaltungen nicht in die erste oder zweite Reihe setze. :-)
 Nach dem Spaß wurde es nun ernst. Mein erster Workshop war Forenlinks 2.0 mit Nicole Mank. Obwohl ich nicht reserviert hatte, bekam ich doch noch einen Sitzplatz.
Nach dem Spaß wurde es nun ernst. Mein erster Workshop war Forenlinks 2.0 mit Nicole Mank. Obwohl ich nicht reserviert hatte, bekam ich doch noch einen Sitzplatz.
Es war durchaus interessant zu sehen, was beim Linkaufbau über Foren zu beachten ist. Eine allzu plumpe Vorgehensweise (Anmelden, Post mit Link schreiben, nicht mehr blicken lassen) wird in großen Foren wohl kaum erfolgreich sein.
Ich sehe das eher aus der Sicht eines Forennutzers, der durch zu spammige Linkaufbau-Posts genervt ist. Gut zu wissen, wie Forenlinks aufgebaut werden, so kann ich sie besser erkennen und den Mods ggf. melden, wann mir etwas in der Richtung verdächtig erscheint. :-)
 Zum zweiten Workshop Welcome to a running System mit Karl Kratz ging ich wieder in den großen Saal. Das war auch schon ein kleines Manko, denn in den letzten beiden Jahren fand ich es in den kleinen Räumen irgendwie kuschliger. :-) Aber gut, dieses Jahr wurde halt dem großen Interesse an Karls Vorträgen Rechnung getragen.
Zum zweiten Workshop Welcome to a running System mit Karl Kratz ging ich wieder in den großen Saal. Das war auch schon ein kleines Manko, denn in den letzten beiden Jahren fand ich es in den kleinen Räumen irgendwie kuschliger. :-) Aber gut, dieses Jahr wurde halt dem großen Interesse an Karls Vorträgen Rechnung getragen.
Karl zeigte uns sein erfolgreich laufendes System zur Vermarktung seines eBooks in allen Phasen des Geschäftsprozesses. Das ist zwar alles sehr interessant, für mich aber insgesamt nicht wirklich relevant, da ich nicht vorhabe, demnächst etwas ähnliches zu tun. Spannend fand ich hingegen die Vorstellung der technischen Möglichkeiten des User-Trackings, sogar vorbei an Cookies, HTML5 Local-Storage und Flash.
 Im nächsten Workshop ging es um Duplicate Content Extreme mit Fabian Drescher. Hier kam ich etwas zu spät und mußte mit einem Stehplatz in der Nähe der Tür vorlieb nehmen. Dadurch hatte ich aber die Gelegenheit zu einem kurzen Schwätzchen mit Dina Lewicki, die auch nur einen Stehplatz hatte. :-)
Im nächsten Workshop ging es um Duplicate Content Extreme mit Fabian Drescher. Hier kam ich etwas zu spät und mußte mit einem Stehplatz in der Nähe der Tür vorlieb nehmen. Dadurch hatte ich aber die Gelegenheit zu einem kurzen Schwätzchen mit Dina Lewicki, die auch nur einen Stehplatz hatte. :-)
Zunächst erläuterte Fabian, was Duplicate Content (DC) ist, wie Google ihn erkennt und wo er oft entsteht. Anschließend entwickelte sich eine rege Diskussion darüber, wie Duplicate Content vermieden, entschärft oder in Near Duplicate Content (NDC) umgewandelt werden kann. Hier konnte ich einige Anregungen mitnehmen.
 Im großen Saal wurden dann von Marcus Tandler und Andreas Bruckschlögl The 10 best Links we ever built vorgestellt. Es waren dann sogar deren 10+2.
Im großen Saal wurden dann von Marcus Tandler und Andreas Bruckschlögl The 10 best Links we ever built vorgestellt. Es waren dann sogar deren 10+2.
Die meisten dieser wirklich hochkarätigen Links sind oder waren schon etwas älter was auch zeigt, daß das heute wohl nicht meht so einfach möglich ist. Um welche Links konkret es ging, darf ich hier zwar nicht schreiben, aber insgesamt war es eine unterhaltsam Darbietung.
 Meine letzter Workshop am Samstag war dann Vergesst die Bildersuche von Ingo Henze. Gut, daß ließ sich nicht vermeiden, da mußte ich hin. :-)
Meine letzter Workshop am Samstag war dann Vergesst die Bildersuche von Ingo Henze. Gut, daß ließ sich nicht vermeiden, da mußte ich hin. :-)
Für alle die, die nicht da waren gibt es hier die Folien als PDF-Datei (3,3 MB):
SEO Campixx 2013 – Vergesst die Bildersuche
Da nicht alle Folien selbsterklärend sind, weil sie Bestandteil meines Vortrags waren, könnt Ihr gerne Fragen stellen, falls etwas unklar ist. Ich werde aber demnächst auch einen Teil hier noch etwas ausführlicher als Blogartikel veröffentlichen.



Zum Abendessen gab es Livemusik und anschließend das schon legendäre „Wer wird SEOnär“. Chef-Fotograf Gerald Steffens war praktisch auch allgegenwärtig.
Gegen 22.30 Uhr machte ich mich auf den Weg zur Bushaltestelle und hatte unterwegs noch Begegnungen mit ein paar Tieren. Rechts im Wald hüpften ein paar Rehe durchs Gelände und links neben mir hörte ich plötzlich ein Schnaufen und Grunzen. Dann sah ich einen größeren, dunklen Schatten im Unterholz, der sich in Richtung Hotel bewegte. Es dürfte wohl ein Wildschwein gewesen sein. Ein schöner Abschluß für einen langen Tag.
 Am Sonntag morgen war es dann nur noch halb so kalt wie am Samstag. Statt -8 waren es nur noch -4 °C, das eigentlich winterliche war der eisige Wind. Mit dem Bus X69 ging es wieder zur Müggelseeperle. Auf dem Weg zum Tagungshotel liefen mir auch keine Wildtiere über den Weg.
Am Sonntag morgen war es dann nur noch halb so kalt wie am Samstag. Statt -8 waren es nur noch -4 °C, das eigentlich winterliche war der eisige Wind. Mit dem Bus X69 ging es wieder zur Müggelseeperle. Auf dem Weg zum Tagungshotel liefen mir auch keine Wildtiere über den Weg.
Der zweite Tag der SEO-Campixx 2013 stand auf dem Programm.
 Der erste Workshop war sehr technisch. Markus Uhl refreriert über Scraping Basics: Reguläre Ausdrücke und XPath. Es ist nun nicht so, daß ich dort etwas grundlegend Neues zu Regulären Ausdrücken erfahren hätte, aber oft sind andere Herangehensweisen oder Ansätze eine Quelle für eigene Ideen.
Der erste Workshop war sehr technisch. Markus Uhl refreriert über Scraping Basics: Reguläre Ausdrücke und XPath. Es ist nun nicht so, daß ich dort etwas grundlegend Neues zu Regulären Ausdrücken erfahren hätte, aber oft sind andere Herangehensweisen oder Ansätze eine Quelle für eigene Ideen.
Gerade mit Regular Expressions kann eine Problemstellung mit unterschiedlichen Lösungen erschlagen werden, die alle ihre Vor- und Nachteile haben. Für mich war dieser Workshop die absolut richtige Wahl. Zum XPath gab es dann aus Zeitmangel nur eine Schnelldurchlauf, was micht aber nicht weiter gestört hat.
 Mit Expired Domains habe ich zwar nichts am Hut, aber im Workshop WDF/IDF in der Praxis – perfekter Wiederaufbau von Expireds von Lambertus Kobes ging es eben auch um WDF/IDF.
Mit Expired Domains habe ich zwar nichts am Hut, aber im Workshop WDF/IDF in der Praxis – perfekter Wiederaufbau von Expireds von Lambertus Kobes ging es eben auch um WDF/IDF.
Zuerst ging es zwar in erster Linie um Expired Domains, aber auch das war recht interessant. Beim Thema WDF/IDF kam dann SEOLyze ins Spiel und so konnte ich mich noch kurz vor dem Ende des Workshops in Richtung Essenausgabe verdrücken.



Eine Mittagspause gab es zwar auch schon am Samstag, aber da war ich nicht rechtzeitig vor dem großen Ansturm vor Ort. Am Sonntag konnte ich dann aber noch relativ ungestört die Happahappa-Sachen fotografieren. :-)
 Gut gesättigt ging es dann zu Jens Altmann in Histologische Analyse Computeraffiner Kreativer nebest Treffen Einer Luminösen Liga.
Gut gesättigt ging es dann zu Jens Altmann in Histologische Analyse Computeraffiner Kreativer nebest Treffen Einer Luminösen Liga.
Hä, bitte was??? Genaus so ging es mir und vielen anderen auch. Jens hatte mir beim Mittagessen allerdings schon verraten, daß man da etwas zwischen bzw. neben den Zeilen lesen mußte und so wußte ich schon in etwa, was mich erwartet.
Zum Inhalt darf ich nichts schreiben. Es sie nur soviel gesagt, es war höchst interessant und anregend. Nicht das ich die gesehenen Dinge nun so direkt anwenden will, aber es gab einige Denkanstöße. Danke dafür!
 Vom SEO-Tool Manhattan hatte ich bis zur Mittagspause noch nichts gehört, aber Inside klang irgendwie spannende und so bin ich zu Fabian Brüssel mit Inside Manhattan gegangen. Die Jungs von Manhattan haben ihre Server im eigenen Keller zu stehen, was natürlich Vor und Nachteile hat.
Vom SEO-Tool Manhattan hatte ich bis zur Mittagspause noch nichts gehört, aber Inside klang irgendwie spannende und so bin ich zu Fabian Brüssel mit Inside Manhattan gegangen. Die Jungs von Manhattan haben ihre Server im eigenen Keller zu stehen, was natürlich Vor und Nachteile hat.
Interessant war auch der Einblick in die verwendete Software. Ich muß mir bei den lächerlichen 9000 Keywords für den Bidox also noch keine Sorgen machen, auch deutlich größere Datenmengen sind mit MySQL noch handhabbar. Allerdings habe ich auch keine 30 Server im Keller zu stehen. :-)
 Den Abschluß des Tages und der Campixx 2013 bildete für mich der Workshop Large Scale White Hat Link Building mit Eric Schulz. Nach einigen anfänglichen Irritationen lichtete sich der Nebel und es kam ein interessantes Linkbuilding-Konzept zum Vorschein.
Den Abschluß des Tages und der Campixx 2013 bildete für mich der Workshop Large Scale White Hat Link Building mit Eric Schulz. Nach einigen anfänglichen Irritationen lichtete sich der Nebel und es kam ein interessantes Linkbuilding-Konzept zum Vorschein.
Falls ich mal in die Verlegenheit kommen sollte, Links für meine eigenen Seiten aufzubauen, würde ich wohl einen ähnlichen Weg gehen.
Und da war sie schon wieder vorbei, die SEO-Campixx 2013. Vielleicht sehen wir uns ja im nächsten Jahr, wenn das nächste SEO-Klassentreffen am Müggelsee ansteht.
Besten Dank an Marco Janck und die Campixx-Crew!

Weitere Berichte von der SEO-Campix 2013:

Bei der Putzlowitscher Zeitung hatte ich ja schon gestern meinen Lesern ein Frohes Fest gewünscht, heute will ich das hier auch bei Schnurpsel tun, da wahrscheinlich nicht alle Leser beiden Blogs lesen.
Dieses Jahr gibt es nicht nur Bilder mit Kerzen, sondern ein kleines weihnachtliches Video:

Zudem hatte ich eine Regen-Version erstellt, weil gestern der Wetterbericht für heute Regen angekündigt hatte:

Vom Regen ist im Moment hier nicht viel zu sehen, Schnee aber auch nicht. Bei ca. 6 °C ist es nicht gerade winterlich kalt, eher herbstlich trüb und feucht.
Wie auch immer, laßt es Euch an den Feiertagen gut gehen und erholt Euch ein bißchen. Ich werde das zumindest versuchen. :-)
Ende November hatte ich die ersten deutlichen Bewegungen im Ranking der Google Bildersuche bemerkt. Ich erfasse neben den Daten für den Bidox, die nur wöchentlich abgefragt werden, auch noch täglich die Rankings der Google-Bildersuche bei einigen für mich interessanten Suchbegriffen:
äpfel, aprikosen, auto, bananen, bildersuch, birne, brokkoli, brot, brötchen, burger, champignons, elefant, erdbeere, essen, euro, fenchel, geld, gurke, gurken, hut, kaffee, karfiol, kartoffel, katze, kerzen, kloster chorin, latte macchiato, limetten, mohnbrötchen, mona lisa, münzen, nudeln, orange, pferde, pfirsich, pflaume, pommes, rum, sesambrötchen, tomaten, zigarren
Gut, das ist jetzt nicht gerade eine repräsentitive und zudem viel zu kleine Stichprobe, aber wenn etwas passiert, war das bisher immer ein Zeichen für größere Veränderungen.
Zum einen werden beim Blick auf die Top-10-Diagramme Bewegungen schnell sichtbar:
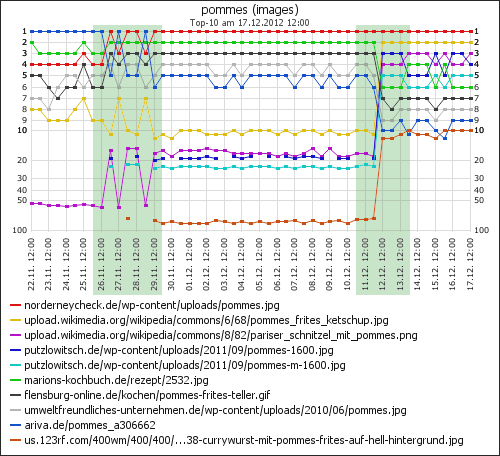
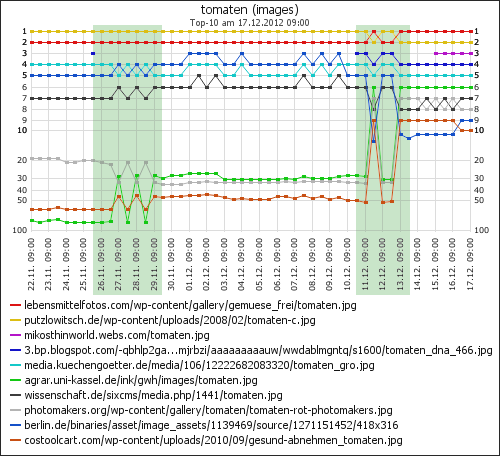
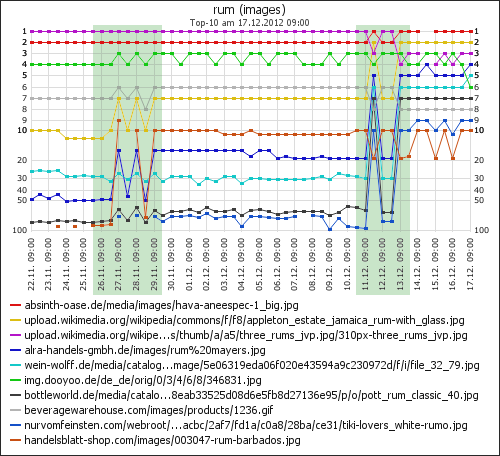
Außerdem habe ich die vom 10.11. bis heute pro Tag neu in die Top-100 gekommen Bilder in einem Diagramm dargestellt:

Gut zu sehen ist das erste Ranking-Update in der Zeit vom 26.11. bis 29.11. und auch das zweite Update vom 11. bis 13. Dezember.
Im Bilder-Domain-Index werden diese Veränderungen dann auch sichtbar.
Der große Gewinner der beiden Ranking-Updates in der Google-Bildersuche ist der Stock-Foto-Anbieter 123rf.com:

Beim ersten Update stieg der Bidox von etwa 11 auf 131 (Platz 200 -> 7), aktuell liegt der Bidox bei gut 570, was Platz 3 hinter Wikipedia und Blogspot bedeutet.
Für 123rf.com ist das gewissermaßen ein Wiederaufstieg zu neuen Höhen, denn zu Anfang des Jahres lag die Domain mit einem Bidox von knapp 70 schon mal auf Platz 17:

Zu den Gewinnern zählt aber nicht nur 123rf.com, sondern weitere Bilder-Communities (z.B. fotocommunity.de) und Stock-Foto-Dienste (z.B. depositphotos.com). Im TagSeoBlog von Martin Mißfeldt gibt es eine ausführliche Betrachtung von weiteren Gewinnern und Verlierern.

Nach dem Allzeit-Hoch in der Kalenderwoche 48 mit knapp 1754 Bidox-Punkten gab es nun einen Verlust von gut 10 Prozent auf 1565. Das bedeutet natürlich keinen Verlust in der Bidox-Platzierung. Hier liegt die Wikipedia auch weiterhin unangefochten auf Platz 1.
Aber auch die Anzahl der Bilder ist nicht etwa gefallen, sondern sogar angestiegen (+895). Der Bidox-Verlust erklärt sich aus dem Ranking-Verlust, besonders bei den Plätzen 1 und 2.
Deutlich wird das beim Vergleich der Anzahl der Top-5 Bilder mit der vergangen Woche:
| Position | KW 49/2012 | KW 50/2012 | ± Anzahl | ± in Prozent |
|---|---|---|---|---|
| 1 | 1145 | 591 | -554 | -48,4% |
| 2 | 532 | 369 | -163 | -30,6% |
| 3 | 242 | 270 | +28 | +11,5% |
| 4 | 160 | 243 | +83 | +51,9% |
| 5 | 143 | 222 | +79 | +55,2% |
Für Platz 1 und 2 hatte die Wikipedia gewissermaßen ein Abo, wie man das auch aus der normalen Suche kennt. Allerdings war das auch noch nicht immer so. Deutlich wurde das erst mit den Ranking-Updates vom Juni 2011 und November 2011.
Nun hat Google scheinbar den Wikipedia-Bonus etwas zurück gedreht, so daß auch kleine Websites wieder Chancen haben, für einfache Sachbegriffe wie Äpfel, Aprikosen, Brot und Brötchen den ersten und zweiten Platz in der Bildersuche zu belegen.

Insgesamt kann ich mich zu den Gewinnern der jüngsten Ranking-Updates zählen. Mein Blog putzlowitsch.de und meine Hotlink-/Bilder-Galerie bilderu.de haben im Bidox zugelegt. Bei Putzlowitsch habe ich gewissermaßen den umgekehrten Wikipedia-Effekt. Ich habe zwar insgesamt 3 Bilder weniger im Index, dafür aber auf Platz 1 und 2 zusammen 3 Bilder mehr.
Seit einigen Tagen gibt es ihn auch in den deutschen Suchergebnissen, den Google Knowledge-Graph. So sieht er z.B. für den Suchbegriff Kartoffeln aus:

Wenn Google zu Suchbegriffen wie etwa berühmten Personen, Städten, Sportmannschaftenn, Gebäuden, Filmen, Kunstwerken und anderen Fakten im Wissensgraphen findet, werden diese Informationen direkt in einer Box rechts neben den Suchergebnissen angezeigt.
Bei meinen Betrachtungen geht es hier nur um gegenstädliche Sachthemen wie Obst, Gemüse und Speisekartoffeln, nicht aber um Personen, Kunstwerke, Orte und Ähnliches. Der Inhalt, Umfang und die Darstellung der Daten hängt eben auch vom Themengebiet ab.
Der Text in der Knowledge-Graph-Einblendung stammt bei Sachthemen aus der Wikipedia, zumindest habe ich noch keine anderen Quellen gesehen, und verlinkt auf den passenden Wikipedia-Artikel. Der Text steht entweder trocken ohne Bild in der Box, oder es gibt ein Bild oder mehrerer Bilder. Der Fall ohne Bild ist hier nicht weiter interessant, denn es geht mir hier um die Bilder und die Bildersuche.
Die Frage ist nun, wo kommen das Bild oder die Bilder her, welche im Knowledge-Graph angezeigt werden.
Die Herkunft der Bilder hängt von der angezeigten Anzahl der Bilder ab. Der für mich als Bildermensch beste Fall sind natürlich viele Bilder (wie im obigen Kartoffel-Beispiel).
Nach meinen bisherigen Beobachtungen kommt das erste, vergrößert dargestelllte Bild immer aus englischsprachigen Quellen. Dazu weiter unten noch ein paar Beispiele. Die anderen Bilder, etwa 4 bis 8 an der Zahl, sind die Bilder aus der Bildersuche und zwar genau die ersten entsprechend der Anzahl in der KG-Box:

Zur Verdeutlichung habe ich eine verkleinerte Ansicht der Bildersuchergebnisse eingeblendet. Die 6 Bilder neben dem großen Bild im Knowledge-Graph sind die Bilder Nummer 1 bis 6 aus der Bildersuche und zwar zum eingegebenen Suchbegriff Kartoffeln (Mehrzahl) und nicht zum angezeigten Wort Kartoffel (Einzahl).
Und noch etwas ist anders, die Universal-Search Bilder-OneBox auf der ersten Seite ist verschwunden. Die Bilder sind gewissermaßen von der Universal-Serach in den Knowledge-Graph gewandert. Aber das ist nur die halbe Wahrheit:

Auf der zweiten Treffer-Seite gibt es sie dann doch, die Bilder-OneBox. Hier landen dann weitere Bilder aus der Bildersuche, die nicht in der Knowledge-Graph-Box angezeigt werden. Bei den Kartofflen z.B. die Bilder 7 bis 10 aus der Bildersuche.
Falls nur ein oder kein Bild im Knowledge-Graph angezeigt wird, bleibt die normale Universal-Search-Box auf der ersten Seite an ihrer normalen Position erhalten (sofern es vorher schon eine gab):

Wie oben schon angedeutet, stammt das vergrößert dargestellte Top-Bild bzw. das einzelne Bild, wenn es nur eins gibt, aus einer englischsprachigen Quelle. Das ist oft die englische Wikipedia, aber es gibt auch andere Quellen. Hier ein paar Beispiele:

Zum Pfirsich gibt es ein Bild aus der englischen Wikipedia, verlink mit dem entsprechenden Artikel Peach.

Das einzelne Pflaume Bild stammt aus einem Artikel bei einer EDU-Seite, der „Purdue University“, mithin eine gewisse Autorität.

Die Kartoffel kommt von der Seite einer Umweltbewegung, auf der der Gewinner eines Kartoffel-Wettbewerbes bekannt gegeben wurde.

Das Top-Bananen-Bild von der „Banana Café & Piano Bar“ ist zwar lustig, ich finde es aber für den Knowledge-Graph nicht unbedingt optimal. Es ist mir etwas zu unseriös, um nicht zu sagen, albern. :-)

Bei der Tomate wird das Bild einer Tüte Tomatendünger einer Gärtner-Seite im Knowledge-Graph angezeigt. Aus meiner Sicht ist das auch nicht unbedingt die beste Wahl. Da gibt es passendere und schönere Tomaten-Bilder.
Warum auch im deutschen Google Knowledge-Graph als Haupt-Bild nur solche aus englischsprachigen Quellen angezeigt werden, ist für mich nicht wirklich nachvollziehbar. Gut, ein Bild ist ein Bild, das sollte weitestgehend sprachunabhängig sein. Aber die Auswahl der Bilder ist durchaus Verbesserungsfähig und außerdem ist es für Bilder aus dem deutschsprachigen Raum schade, wohl (vorerst) nicht das vergrößerte Top-Bild oder Einzelbild stellen zu können.
Auf einen kurzen Nenner gebracht, die Knowledge-Graph-Box ist die neue Bilder-OneBox.
Gut, das trifft nicht immer zu, aber wenn es der Fall ist, könnte es durchaus ein mehr an Besuchern bringen. Leider wird man es aus deutscher Sicht mit einem Bild wohl nicht auf den Platz an der Sonne im Knowledge-Graph schaffen und die weiteren Bilder werden etwas kleiner als in der Universal-Search-Einblendung dargestellt.
Aber insgesamt ist bei gegenständlichen Sachthemen ein Bild wohl die einzige Möglichkeit in der Knowledge-Graph-Box überhaupt mitzumischen. Na dann, auf zum Bilderoptimieren. :-)
Nachtrag: Ein Aspekt ist mir noch eingefallen. Wie gehen eigentlich die SEO-Tool-Anbieter, die auch die Universal-Search Ergebnisse erfassen (z.B. SISTRIX, SEOlytics, Searchmetrics), mit der veränderten Situation um? Die Bilder in der Knowledge-Graph-Box entsprechen ja nun teilweise den Universal-Search-Ergebnissen (außer Bild 1). Die Bilder in der KG-Box müssen somit auch erfaßt werden, denke ich.
Anders gesagt, plötzlich deutliche Verluste in der Universal-Search (Bilder) könnten an der Einführung des Knowledge-Graph liegen.