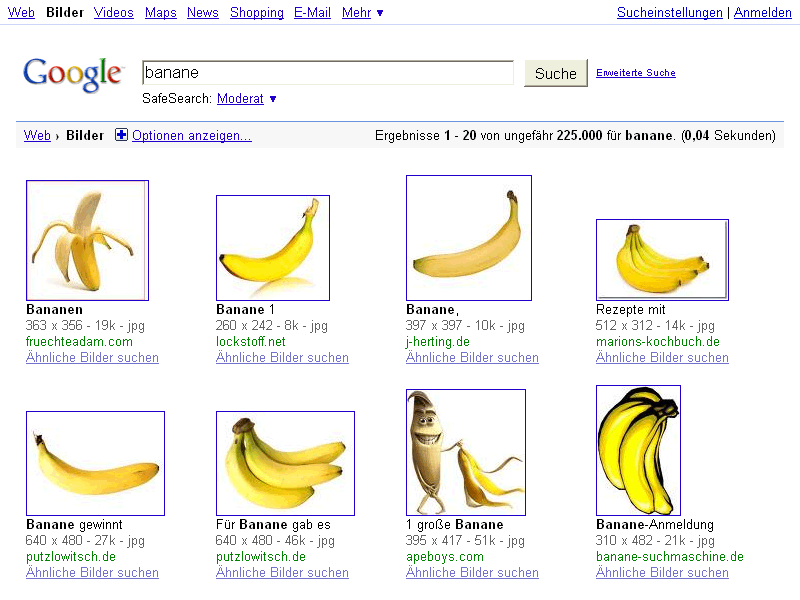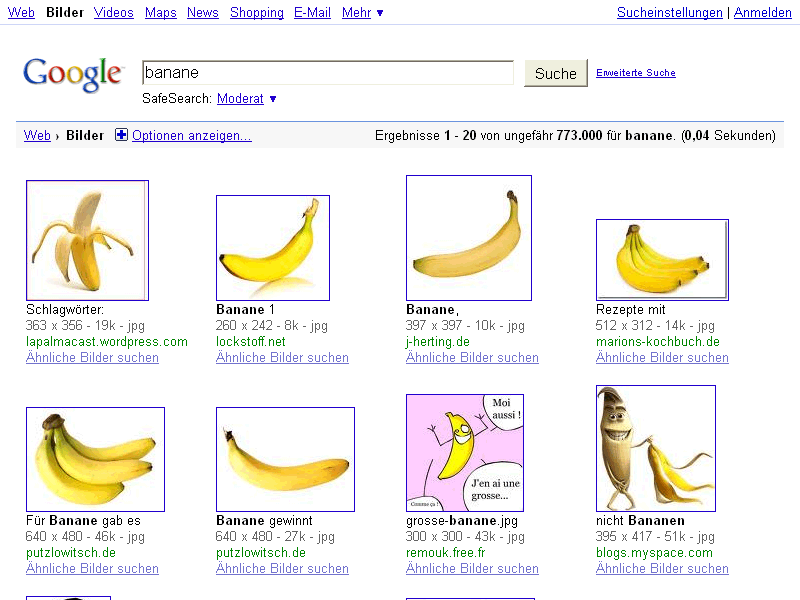
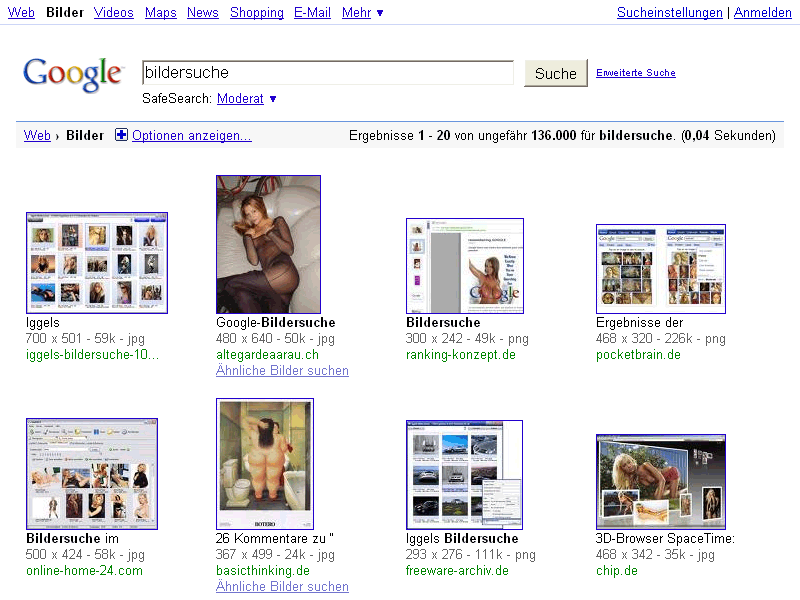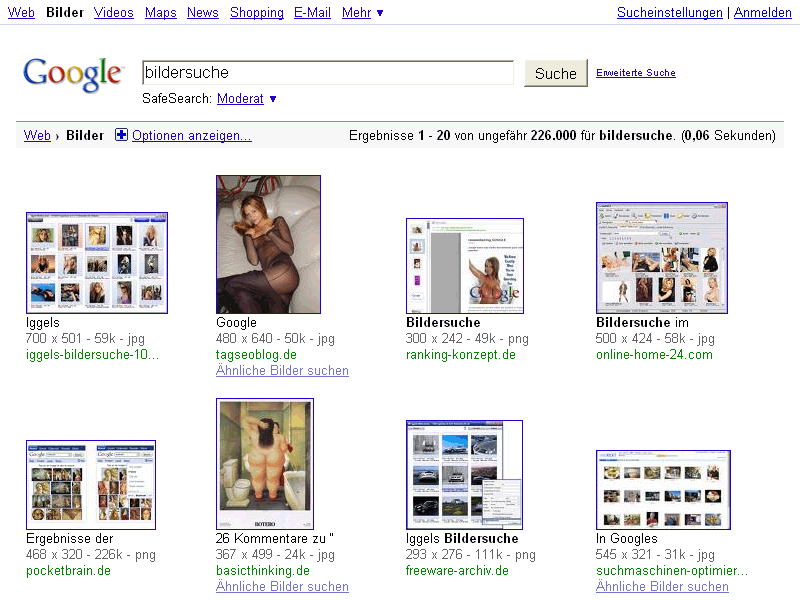
Klar gibt es duplicate content (DC) bei der Bildersuche. Wenn ein Bild als Kopie mehrfach existiert, dann ist das „Duplizierter Content„. Es gibt bestimmt nicht wenige Bilder, die nicht nur zweifach, dreifach sondern tausendfach, ja sogar millionenfach existieren. :-)
Nehmen wir nur diese kleinen Kollegen hier, die kommen bestimmt in fast jedem Forum oder Blog dieser Welt vor. Das eigentliche Problem für die Suchmaschinen ist nun, welches der mehrfach vorhandenen Bilder optimalerweise in den Suchergebnissen angezeigt wird.
Instabiles Brötchen

Durch die Brötchen-Ritter-Aktion habe ich seit Ende Januar 2010 die Brötchenbilder unter Beobachtung. Dabei ist mir eher zufällig das Bild auf Platz 9 der Bilder-Suchergebnisse aufgefallen. Das Bild ist immer dasselbe, nur die Bild-URL und referenzierende Seite änderten sich ständig. Des Rätsels Lösung ist erstmal recht einfach, die Website der Bäckerei Soetebier existiert unter drei Domainnamen. Unter www.ihr-broetchendienst.de, www.dorfbaeckerei-soetebier.de und www.baeckerei-soetebier.de werden identische Inhalte und auch identische Bilder angezeigt.
Google konnte sich vom Beginn meiner Brötchenbeobachtung für etwa 10 Tage nicht für eine Seite enscheiden. Ist auch nicht einfach, bei exakt denselben Inhalten und Bilddaten. Die Onpage-Faktoren könne so kaum einen Anhaltspunkt liefern.
Brötchen fast stabil

Ungefähr ab dem 11. Februar bis zum 6. März ist dann eine recht stabile Phase zu beobachten, die nur wenige, einzelne Aussetzer beinhaltet. Google hatte sich für die Domain www.dorfbaeckerei-soetebier.de entschieden. Aber warum? Darüber kann ich jetzt nur spekulieren.
Ein paar Onpagefaktoren gibt es natürlich schon, wenn man einen Bezug zum Domainnamen herstellt. So wird auf der Startseite gleich am Anfang die „Dorfbäckerei Soetebier“ genannt. Zudem gib es auf jeder Seite im Kopfbereich die Kontaktdaten, wo mit einer E-Mail-Adresse auf dorfbaeckerei-soetebier.de verwiesen wird. Das spricht für die Dorfbäckerei-Domain.
Andererseits steht im Titel-Tag der meisten Seiten „Bäckerei Soetebier“ ohne Dorf, was eher auf die Nur-Bäckerei-Domain hindeutet. Schließlich findet man den Begriff Brötchendienst überhaupt nicht auf einer der Seiten, was gegen „Ihr Brötchendienst“ spricht.
Das alles hilft zwar vielleicht für Dorfbäckerei oder Bäckerei, aber nicht beim konkreten Suchbegriff „Brötchen“ weiter, denn dafür würde ich ihr-broetchendienst.de favorisieren. Schließlich ist dort das Keywort im Domainnamen enthalten.
Vermutlich spielen eher die externen Faktoren wie die Verlinkung eine wichtigerer Rolle. Dazu habe ich den Yahoo-Siteexplorer befragt und ein recht überschaubares Ergebnis erhalten. Rein quantitativ betrachtet liegt hier dorfbaeckerei-soetebier.de mit 11 Backlinks vor baeckerei-soetebier.de mit nur 4 Links. Die Domain ihr-broetchendienst.de kennt Yahoo (noch) nicht.
Das Alter einer Domain läßt sich ja für DE-Domains nicht direkt ermitteln. Netcraft sagt für alle drei Domains „first seen“ September 2001. Bei der WayBack-Machine findet man für baeckerei-soetebier.de den ersten Eintrag vom Mai 2001, für dorfbaeckerei-soetebier.de vom August 2002 und für ihr-broetchendienst.de gar nichts.
Plausibel oder irgendwie nachvollziehbar ist das alles aber nicht.
Brötchen wieder in Bewegung

Seit nunmehr über drei Wochen denkt Google wieder drüber nach, welche Seite denn nun für das Brötchenbild am relevantesten ist. Dieser Zeitraum deckt sich übrigens recht gut mit den schon länger anhaltenden Schwankungen in der Bildersuche. Sollte die Bildersuche insgesamt nun dynamischer geworden sein, als jemals zuvor?
Wie auch immer, Duplicate Content stellt für die Bildersuche selbst kein Problem dar. Nur für die Suchmaschine ist die Entscheidung schwerer, welche Seite denn für ein Suchergbnis konkret angezeigt werden soll.
Dem Bildersuchenden kann es letztendlich egal sein, denn er sucht ja das Bild. Und Bild bleibt Bild, egal auf welcher Website.
Nachtrag 8. April:
Da hatte ich diesen Artikel hier grad fertiggestellt und was passiert einen Tag später? Es kommt eine weitere Bäckerei-Domain hinzu:
")
Für diese neue aufgetauchte Domain www.ihr-online-beacker.de trifft dasselbe zu, wie für www.ihr-broetchendienst.de. Der Yahoo-Sitexplorer kennt sie nicht, Netcraft behauptet „first seen“ im September 2001 und die WayBack-Machine findet gar nichts.
Mal sehen, wieviele Domains in Zukunft noch hinzukommen … :-)