
Das Problem
In den letzten Tagen ist die Aufregung ob der neuen Google-Bildersuche recht groß und viele versuchen, einen Ausweg aus den sinkenden Besucherzahlen zu finden.
In der neuen Bildersuche werden die Bilder direkt in Original-Auflösung auf der Ergebnisseite geladen. Der Nutzer hat also wenig Anlaß, die Ursprungsseite zu besuchen.
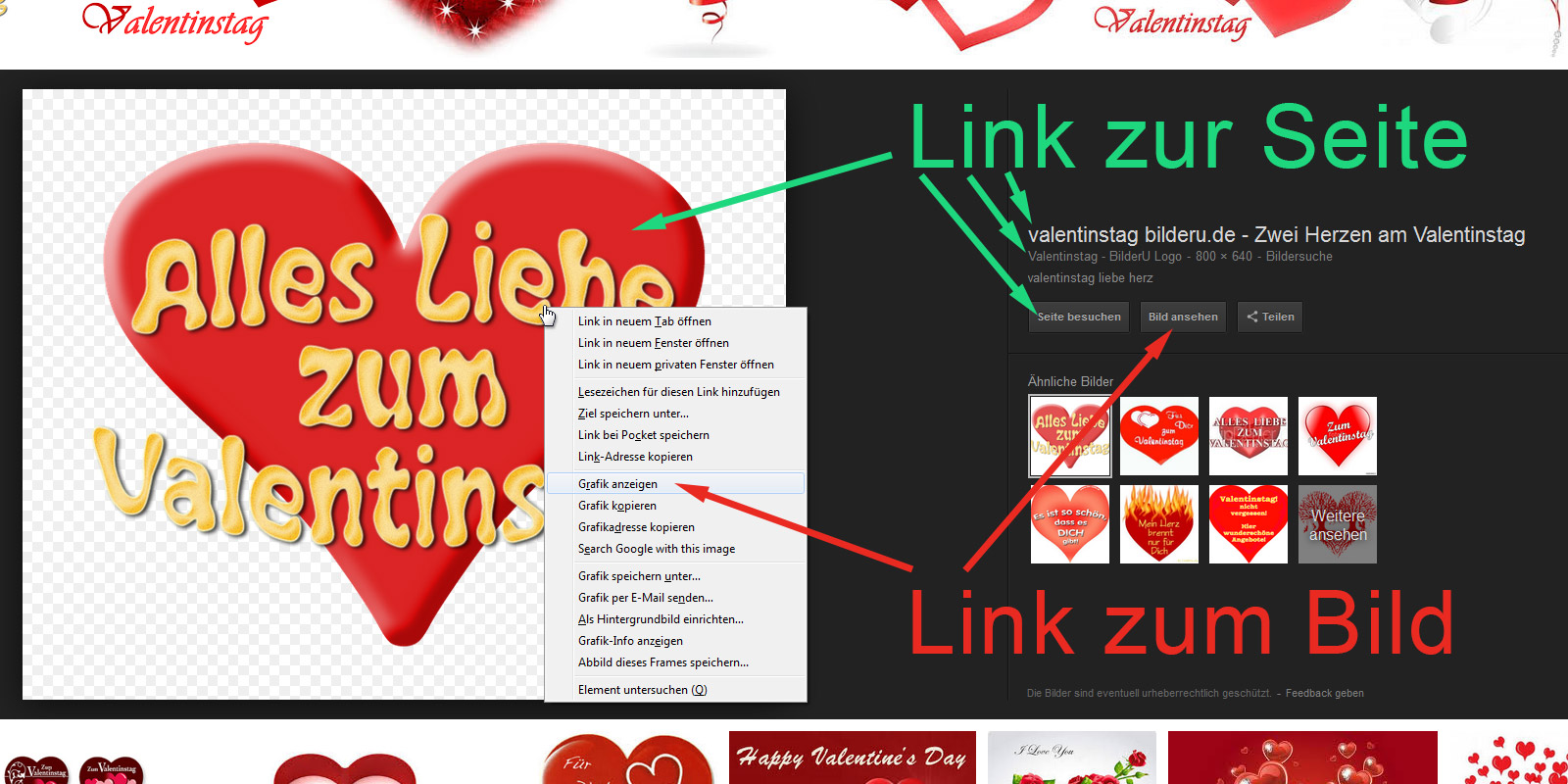
Google-Bildersuche: Links zu Seite/Bilder
Immerhin gibt es vier Links (grün), die den Benutzer auf die Ursprungsseite mit dem Bild führen. Dazu kommt ein Link direkt zum Bild [Bild ansehen] und indirekt die Möglichkeit, per Rechtsklick und „Grafik anzeigen“ nur das Bild aufzurufen.
Der direkte Link zum Bild bringt allerdings keine Besucher auf die Seite. Daher gibt es die Idee, den direkten Aufruf eines Bildes aus der Bildersuche auf eine Seite mit dem Bild umzuleiten.
Achtung!
Lest bitte vorher die Hinweise von Google zu „Bilder-Cloaking“ und überlegt Euch, ob Ihr das Riskio eingehen wollt.
So gehts
Um zu erkennen, ob jemand von der Bildersuche kommt, kann man den Referrer auswerten. Vereinfacht gesagt, könnte man folgende Regel formulieren:
„Ist die Referrer-Domain google.* und die angeforderte Datei ein Bild (jpeg,png,…), dann leite den Nutzer auf eine Seite mit dem Bild um.“
In der .htaccess könnte das so aussehen:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} -f
RewriteCond %{HTTP_REFERER} ^http(s)?://(www\.)?google [NC]
RewriteRule \.(jpg|png|gif)$ /redirect.php [L]
</IfModule>
Zunächst wird Rewrite eingeschaltet und die Basis festgelgt.
Dann wird geprüft, ob es die angeforderte Datei überhaupt gibt und ob der Referrer Google ist. Falls ja und die Datei ein Bild ist, wird das PHP-Skript zur Weiterleitung aufgerufen.
So weit, so gut, nur gibt es noch einige Probleme zu lösen.
Leider wird der Referrer auch gesendet, wenn das Bild als Bild auf der Google-Seite geladen wird. Da soll natürlich keine Weiterleitung erfolgen, weil das im Kontext eines Bilder zu einem Fehler führt. Kann man also unterscheiden, ob das Bild geladen wird oder ein Link auf das Bild aufgerufen wird? Ja, mann kann. Zumindest meistens.
Außerdem wird ein bereits geladenes Bild vom Browser im Cache vorgehalten, was zu unvorhergesehenen Ergebnissen bei der Weiterleitung führen kann. Kann man das verhindern? Ja, man kann.
Meine Problemlösungen
Als technische Basis setze ich einen Apache-Server mit den aktiven Modulen mod_rewrite, mod_headers und mod_setenvif voraus. Wobei das Modul mod_setenvif nicht zwingend erforderlich ist, es macht die Sache aber übersichtlicher:
<IFModule mod_headers.c>
Header set Cache-Control "no-cache, no-store, must-revalidate" env=NO_CACHE
Header unset Expires env=NO_CACHE
Header unset Last-Modified env=NO_CACHE
Header unset ETag env=NO_CACHE
</IfModule>
<IfModule mod_setenvif.c>
SetEnvIf Accept "text/html" REQ_HTML=1
SetEnvIf Referer "^https?://(([^\.]+?\.)?([^\.]+?\.)?[^\.]+?)/" DOM_REFERER=$1
</IfModule>
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /bilder
RewriteCond %{REQUEST_FILENAME} -f
RewriteRule \.(jpg|gif|png)$ - [NC,C]
RewriteCond %{ENV:DOM_REFERER} google\.de$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} google\.at$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} google\.ch$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} example\.com
RewriteRule .* - [E=DO_RDR:1,E=NO_CACHE:1]
RewriteCond %{ENV:REQ_HTML} 1
RewriteCond %{ENV:DO_RDR} 1
RewriteRule ([^-]+)-([0-9]+)\.(jpg|gif|png)$ /bild-$1-$2.html [R=302,L]
</IfModule>
Zur Unterscheidung von Bildaufruf (img src=…) und Link verwende ich den Wert von „Accept“ im HTTP-Request-Header. Nach meiner Beobachtung enthält dieses Header-Feld bei Bild-Aufrufen nicht den Typ „text/html“, beim Aufruf von Links, auch zu Bildern, aber schon. Wenn also „text/html“ im Accept-Header zu finden ist, dürfte es sich um den Link zum Bild und nicht um das Laden des Bildes in der Google-Ansicht handeln.
<IfModule mod_setenvif.c> SetEnvIf Accept "text/html" REQ_HTML=1 SetEnvIf Referer "^https?://(([^\.]+?\.)?([^\.]+?\.)?[^\.]+?)/" DOM_REFERER=$1 </IfModule>
Den Accept-Header werte ich in einer SetEnvIf Anweisung aus und setze eine entsprechende Variable, die ich später in den Rewrite-Regeln auswerten kann. Zudem extrahiere ich in dem Block den Domain-Namen aus dem Referer, da ich diesen auch in anderen Rewrite-Regeln benötige.
RewriteCond %{REQUEST_FILENAME} -f
RewriteRule \.(jpg|gif|png)$ - [NC,C]
Mit den Rewrite-Regeln prüfe ich zunächst die Existenz der Datei und über die Datei-Erweiterung, ob ein Bild aufgerufen wird. Falls nicht, wir der zweite Block der Rewrite-Regeln gar nicht erst ausgeführt.
RewriteCond %{ENV:DOM_REFERER} google\.de$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} google\.at$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} google\.ch$ [NC,OR]
RewriteCond %{ENV:DOM_REFERER} example\.com
RewriteRule .* - [E=DO_RDR:1,E=NO_CACHE:1]
Im zweiten Block wird eine Liste von Referrer-Domains abgearbeitet, für die die Weiterleitung erfolgen soll. In dem Fall sind es die drei Google-Domains, von denen die meisten meiner Besucher kommen (exemple.com ist nur ein Platzhalter). Die Abfrage nach dem Referer kann man natürlich auch anders gestalten. Das hängt halt davon ab, was man damit erreichen will. Hier setze ich mir wieder ein Flag (DO_RDR), das ich später für die Weiterleitung auswerte.
<IFModule mod_headers.c> Header set Cache-Control "no-cache, no-store, must-revalidate" env=NO_CACHE Header unset Expires env=NO_CACHE Header unset Last-Modified env=NO_CACHE Header unset ETag env=NO_CACHE </IfModule>
Außerdem setze ich einen Wert (NO_CACHE), mit dem am Ende geprüft wird, ob das Caching deaktiviert werden soll. Der Block mod_headers steht zwar am Anfang, der Webserver führt diese Anweisungen aber erst ganz zum Schluß aus, kurz bevor die Antwort an den Client gesendet wir. Damit wird das Caching des von Google direkt geladenen Bildes verhinert.
RewriteCond %{ENV:REQ_HTML} 1
RewriteCond %{ENV:DO_RDR} 1
RewriteRule ([^-]+)-([0-9]+)\.(jpg|gif|png)$ /bild-$1-$2.html [R=302,L]
Im dritten Rewrite-Block erfolgt dann die Weiterleitung, falls es sich um einen Link-Request (REQ_HTML) handelt und eine Weiterleitung überhaupt ausgeführt werden soll (DO_RDR).
Wohin weiterleiten?
Ein weiteres Problem kann die eigentliche Weiterleitung sein. Wohin soll die Reise gehen?
Im Beispiel ist das relativ einfach. Die Bilder liegen in einem Unterverzeichnis /bilder/ und der Dateinamen besteht aus Bezeichnung und laufender Nummer. Die Zielseiten mit den Bildern bestehen auch aus Bezeichnung und laufender Nummer. Damit läßt sich schon in der .htaccess Datei die Weiterleitungsregel unmittelbar formulieren.
/bilder/tomaten-7.jpg -> /bild-tomaten-7.html /bilder/banane-23.jpg -> /bild-banane-23.html ...
Schön, wenn man so eine klare Struktur für seine Bilder hat. Ich habe die leider nicht. :-)
RewriteCond %{ENV:REQ_HTML} 1
RewriteCond %{ENV:DO_RDR} 1
RewriteRule .* /rdr.php [L]
Also muß die Weiterleitung z.B. von einem PHP-Skript erledigt werden, in dem man dann praktisch beliebige Weiterleitunsziele adressieren kann.
In WordPress gibt es für die über die Mediathek hochgeladenen Bilder jeweils eine Attachment-Seite. Nun könnte man sich die Informationen zum Weiterleitungsziel aus der WP-Datenbank holen. Aus Performance-Gründen habe ich da einen etwas anderen Weg gewählt.
Für WordPress, wie z.B. hier bei schnurpsel.de, sieht das rdr.php-Skript so aus:
<?php
define( 'THISPATH', dirname(__FILE__) . '/' );
@include( THISPATH.'redir.php' );
function set_404() {
header( "HTTP/1.0 404 Not Found", true, 404 );
echo <<<EOT
<!DOCTYPE html>
<html>
<head><title>404 Not Found</title></head>
<body>
<h1>Not Found</h1>
<p>The requested URL was not found on this server.</p>
</body></html>
EOT;
exit;
}
function set_header( $ctype ) {
@header( "Content-type: $ctype" );
@header( 'Cache-Control: no-cache' );
@header( 'Cache-Control: max-age=0', false );
@header( 'Expires:'.gmdate('D, d M Y H:i:s', 0 ).' GMT' );
}
function redirect( $url, $status = 302 ) {
@header( 'Cache-Control: no-cache, no-store, must-revalidate' );
@header( "Location: $url", true, $status );
exit();
}
$img_uri = urldecode( $_SERVER['REQUEST_URI'] );
$redir_url = $redir_b[$img_uri];
if( !$redir_url && @preg_match( '~(.+?)-(1600|1200)\.(jpg|png|gif)$~', $img_uri, $treffer ) ) {
$redir_url = $redir_b[$treffer[1].'.'.$treffer[3]];
}
if( $redir_url )
redirect( $redir_url );
else {
$img_file = THISPATH.$img_uri;
$img_size = @getimagesize( $img_file );
if( $img_size ) {
set_header( $img_size['mime'] );
@readfile( $img_file );
exit;
}
}
set_404();
?>
Download: rdr.zip
In meinem rdr-Skript includiere ich eine weitere PHP-Datei (redir.php), die nur ein Array mit den Weiterleitungszielen für die Bilder enthält. Falls kein Weiterleitungsziel gefunden wird, gebe ich einfach das Bild selbst aus.
Die redir.php PHP-Datei lasse ich mir von einem Skript durch WordPress erstellen:
<?php
define( 'THISPATH', dirname(__FILE__) . '/' );
define( 'WP_USE_THEMES', false );
define( 'USE_ATTACHMENT_URL', true );
@include( THISPATH.'redir.php' );
require('./wp-blog-header.php');
echo '<pre>';
$args = array( 'post_type' => 'attachment', 'posts_per_page' => -1, 'post_mime_type' => 'image', 'post_parent' => null );
$attachments = get_posts( $args );
if ( $attachments ) {
foreach ( $attachments as $post ) {
$attachment_url = wp_get_attachment_url( $post->ID );
$attachment_uri = @parse_url( $attachment_url, PHP_URL_PATH );
if( USE_ATTACHMENT_URL )
$page = get_attachment_link( $post->ID );
else
$page = get_permalink( $post->post_parent );
if( $page && $attachment_uri && !$redir_b[$attachment_uri] ) {
if( strpos( $page, 'attachment_id' ) === false ) {
$redir_b[$attachment_uri] = $page;
echo "+ $attachment_uri -> $page\r\n";
}
else
echo "- $attachment_uri -> $page\r\n";
}
else
echo "* $attachment_uri -> $page\r\n";
}
}
$export_data = "<?php\r\n\$redir_b = ";
$export_data .= var_export( $redir_b, true );
$export_data .= ";\r\n\r\n?>";
file_put_contents( THISPATH.'new_redir.php', $export_data );
echo '</pre>';
?>
Download: get-redir.zip
Mit der Konstante ‚USE_ATTACHMENT_URL‘ wird festgelegt, ob die Weiterleitung auf die Attachment-Seite (true) oder zur Artikel-Seite mit dem Bild (false) erfolgen soll.
Zum Anfang wird die bestehende ‚redir.php‘ geladen. Es werden dann nur Einträge hinzugefügt, die es noch nicht gibt.
Außerdem prüfe ich, ob es die Attachment-Seite wirklich gibt, denn für Bilder ohne Eltern-Seite bzw. Bilder in nicht veröffentlichten Artikeln wird kein Permalink zurückgeliefert, sonder nur die URL mit dem ‚attachment_id‘-Parameter.
Am Ende wird eine neue Datei ’new_redir.php‘ geschrieben, mit der man dann die alte ‚redir.php‘ ersetzen kann.
Folgende Dateien sind an der Methode beteiligt:
/rdr.php
/redir.php
/wp-content/uploads/.htaccess
In der .htaccess-Datei muß die RewriteBase entsprechend angepaßt werden:
RewriteBase /wp-content/upload
Für meine Putzlowitscher Zeitung enthält das Array etwas mehr als 2000 Einträge. Das ergibt eine Dateigröße von ca. 350k. Wer deutlich mehr Bilder in WP verwaltet, muß sich ggf. etwas anderes einfallen lasse.
So ein Array hat aber den Vorteil, daß ich darin auch beliebige, andere Weiterleitungsziele definieren kann.
Noch ein paar Tips und Hinweise
Falls sich alle Eure Bilder in einem Unterverzechnis befinden, bei WordPress z.B. /wp-content/uploads/, dann packt die .htaccess-Datei genau dort rein. Für alle anderen, normalen Seitenaufrufe wird sie dann gar nicht erst abgearbeitet.
Was irgendwie möglich ist, sollte schon in der .htaccess-Datei erledigt werden. Der Aufruf eines Skriptes, eventuell sogar mit Datenbankabfragen, kostet mehr Server-Leistung und verschlechtert die Performance.
Ihr könnt sogar unterscheiden, ob jemand den Button [Bild ansehen] angeklickt oder per Rechtsklick das Bild aufgerufen hat. Beim Rechtsklick wird ggf. vom Browser als Referer die komplette Google-Such-URL übermittelt. Das kann man zur Unterscheidung auswerten, z.B. ob der Parameter tbm=isch im Referer enthalten ist.
Das Speichern mit Rechtsklick auf das Original-Bild in der Bildersuche funktioniert nicht. Es wird die HTML-Seite des Weiterleitungs-Ziels gespeichert. :-)
Ich habe bisher nur mit wenigen Browsern getestet. Bei denen hat es aber funktionert, wie es soll.
Ich übernehme keine Haftung für Schäden, die möglicherweise durch die Umsetzung der hier vorgestellten Methoden entstehen.






