
 Gestern war das Ende des iPhone4Spiel zwei Wochen her, heute endet die Aufzeichnung der Suchergebnisseiten bei hbgf.de. Auch wenn die Bildersuche nicht Gegenstand des Wettbewerbs war, richte ich immer ein besonderen Blick auf die Bilder. Hier kann man gerade bei neuen Suchbegriffen so mancherlei interessante Beobachtung machen.
Gestern war das Ende des iPhone4Spiel zwei Wochen her, heute endet die Aufzeichnung der Suchergebnisseiten bei hbgf.de. Auch wenn die Bildersuche nicht Gegenstand des Wettbewerbs war, richte ich immer ein besonderen Blick auf die Bilder. Hier kann man gerade bei neuen Suchbegriffen so mancherlei interessante Beobachtung machen.
Die Bildersuche durchläuft mehrere Phasen, die ich nachfolgend etwas näher beleuchten will.
Phase 1 – alte Bilder zum neuen Keyword

Meist findet Google spätestens 24 Stunden, nachdem ein neues Keyword in die freie Wildbahn entlassen wurde, die ersten Bilder. Das sind immer alte Bilder, die bereits länger im Bilderindex vorhanden sind und nun irgendwo im Kontext des neuen Suchwortes auftauchen.
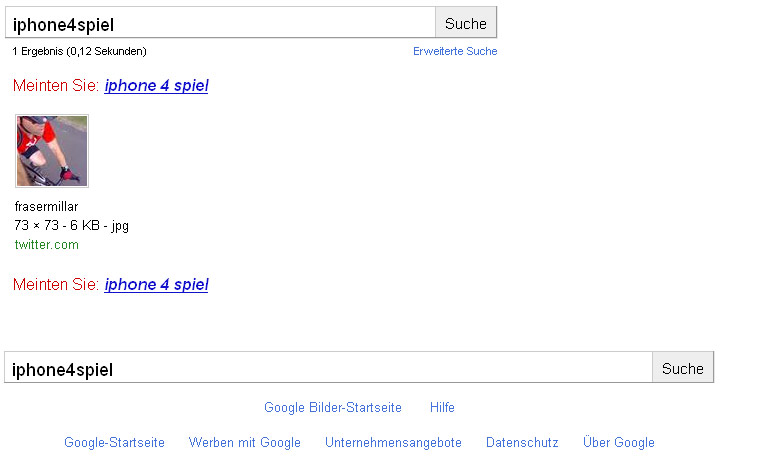
Das erste Bild zum iPhone4Spiel gab es am 17. Juni bei der „Messung“ um 4 Uhr, es war das Twitterprofilbild von @frasermillar, fragt mich aber nicht, warum. Am Nachmittag des selben Tages waren es bereits 37 Bilder.
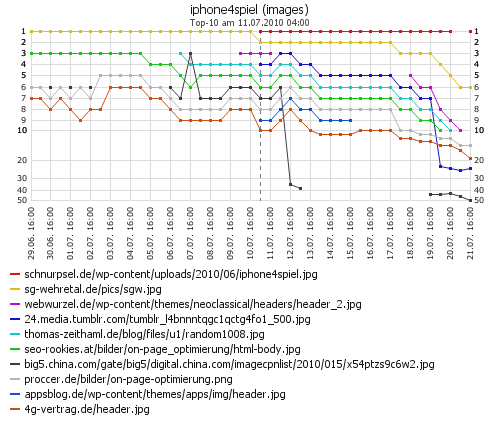
Wie man im Diagramm oben sieht, verschwinden diese Bilder der ersten Stunden dann recht schnell auf den hinteren Plätzen. In der Phase 1 kommen praktisch täglich neue Altbilder hinzu.
Phase 2 – neue Bilder aus den Google-News

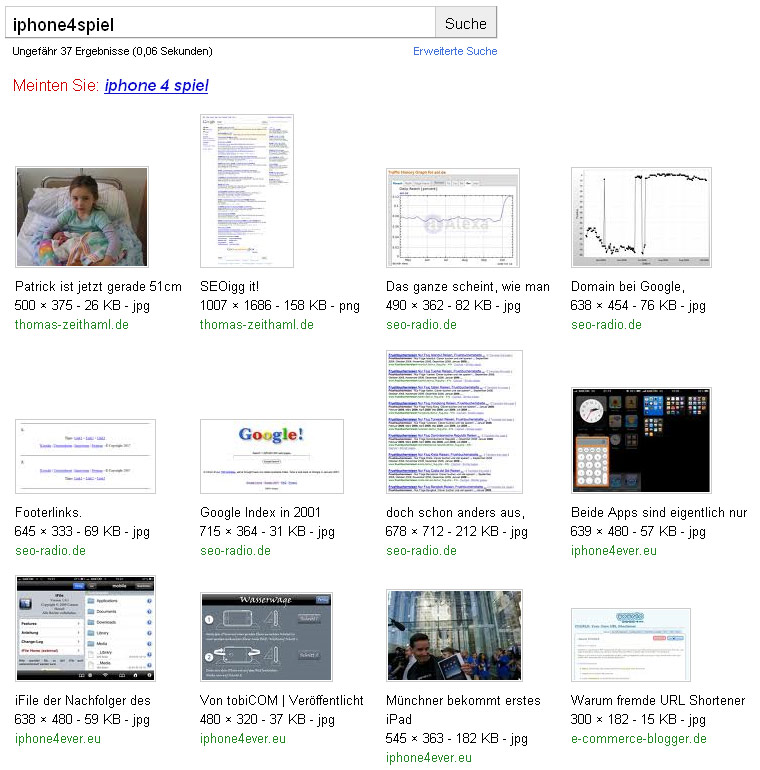
Wo die Phase 1 nicht wirklich etwas Neues bietet, stellt Phase 2 doch ein Novum dar. Erstmals am 19 Juni tauchen echte neue Bilder in der Bildersuche auf. Die beiden Bilder in der unteren Reihe
„Gewinne ein iPhone 4! … Start: 16.06.2010…“
können eigentlich keine alten Bilder sein, denn sie nehmen auf das iPhone4Spiel Bezug, das ja erst am 16. Juni gestartet wurde.
Eine Latenzzeit von gerade mal 3 Tagen wäre schon eine kleine Sensation, benötigten Bilder doch selbst zu Googles besten Zeiten mindestens eine Woche bis in den Bilderindex. Ich hatte das zwar wahrgenommen, aber gedacht, das der Veranstalter die Bilder vielleicht doch schon eher irgendwo ins Internet gestellt hätte oder so.
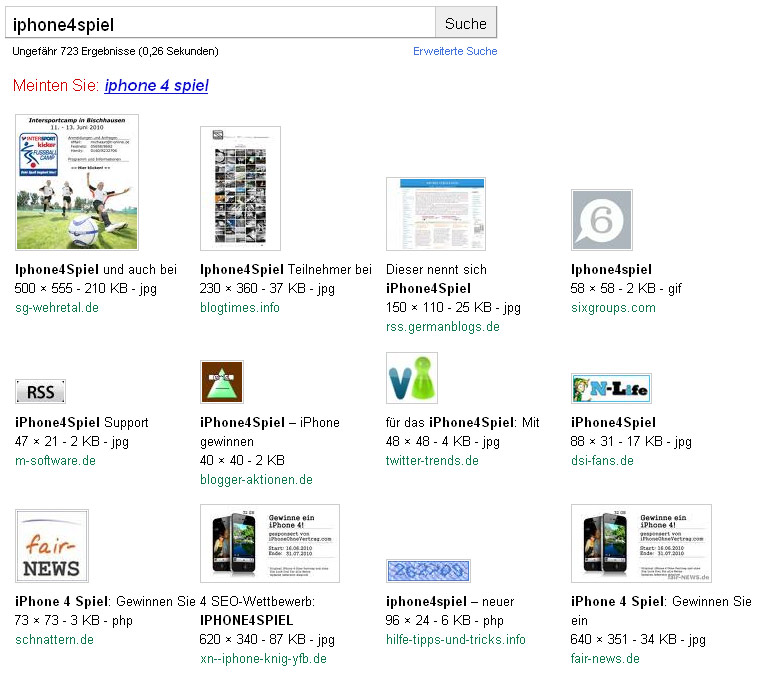
Richtig offensichtlich wurde es dann am 23. Juni, als Bilder auftauchten, die ein nicht vorhersehbares Ereignis aufgriffen und insofern wirklich neu sein mußten. „Interaktiv.net gegen tagSeoBlog“ erschien über die diverse Presseportale in Google-News und somit war klar, das Google Bilder von Newsseiten fast in Echtzeit in den Bilderindex aufnimmt. Auch die schon am 19. Juni auftauchenden Bilder kamen über Google-News in den Index.
Am 25. Juni rutschen die Presseportal-Bilder um bis zu 30 Plätze nach hinten, so daß sie fast mehrheitlich nur noch jenseits der Position 30 oder 40 und damit auf der Trefferseite zwei bzw. drei zu finden sind. Meine Vermutung war nun, daß sie halt genau wie die News-Meldungen nach einer gewissen Zeit nicht mehr interessant sind und deshalb abgewertet werde. Wen interessieren schon Nachrichten oder Bilder von gestern. :-)
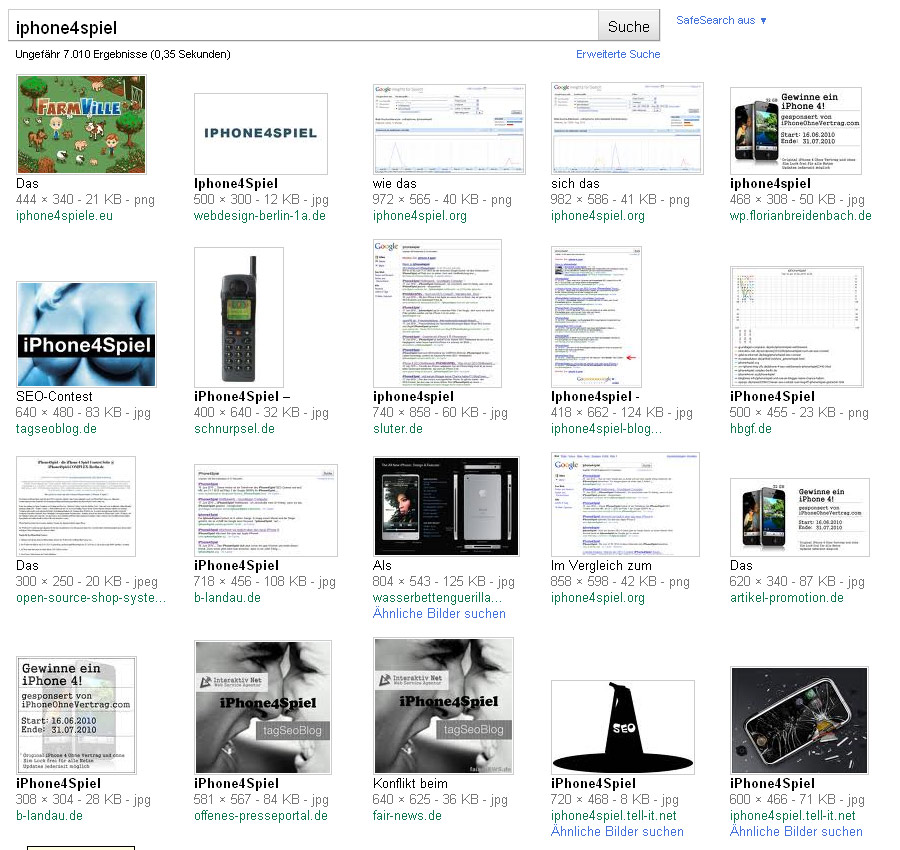
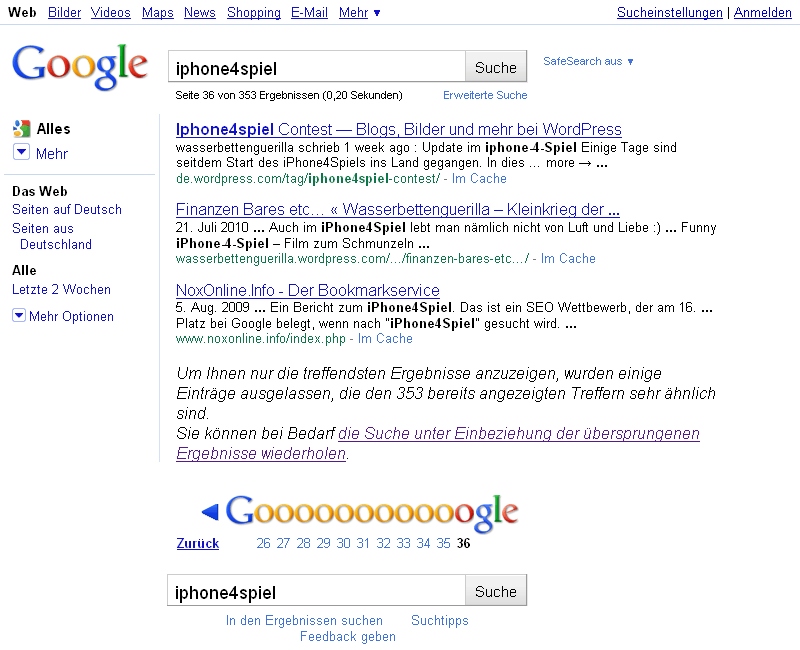
Nun hab ich mir mal die Suchergebnisseiten vom 24. und vom 25. Juni angesehen:


Im Bild links vom 24. Juni werden bei den Ergebnissen noch Google-News eingeblendet, am 25. Juni (Bild rechts) gibt es keine News mehr. Am 25. Juni wurden dann auch die zu den News gehörenden Bilder bei der Bildersuche auf die Trefferseite 2 bzw. 3 durchgereicht (siehe Diagramm oben).
Phase 3 – neue Bilder zum neuen Keyword

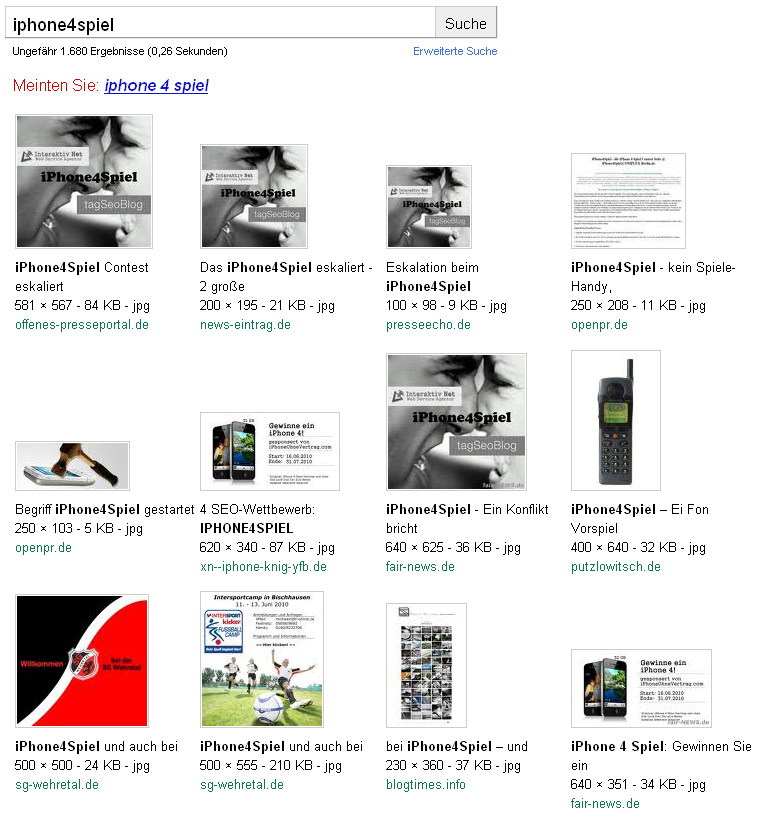
Bis dann die ersten wirklich neuen Bilde auftauchen, passiert eigentlich nicht mehr viel. Es gibt schon noch Bewegung im Bilder-Ranking, bestimmte alte Bilder setzen sich an Positionen fest und dann kommen eventuelle noch alte Bilder im neuen Gewand daher.
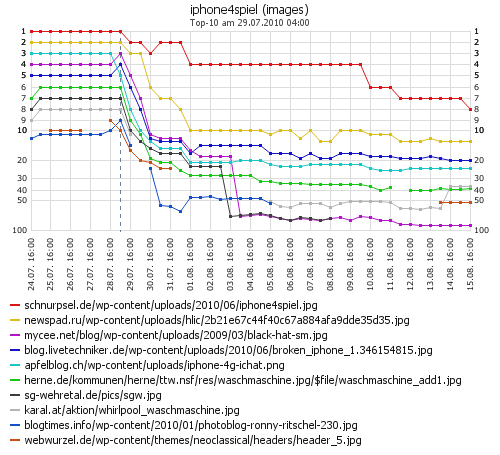
Richtig was los ist dann aber erst wieder mit wirklich neuen Bildern. Das Diagramm oben zeigt die Top 10 am iPhone4Spiel-Stichtag 31. Juli um 16 Uhr. Bereits zwei Tage vorher, am 29. Juli 2010 beginnt das lange erwartete Google-Bilderupdate und damit fallen praktisch alle Altbilder von den ersten Plätzen nach hinten zurück.
Die erste Suchergebnisseite wird nun von neuen Bildern dominiert. Dabei ranken Bilder von Seiten besonders gut, die auch bei der normalen Suche weit vorn liegen und auch ein paar von den News-Bildern tauchen nun regulär wieder auf.
Fazit
Bei einem SEO-Wettbewerb mit einem neuen, bisher nicht bei Google zu findenden Schlüsselwort, kann man den „Lebenszyklus“ der Bildersuche sehr schön verfolgen. Eine wirklich interessante Entdeckung für mich war, daß Goolge Bilder aus den Google-News tagesaktuelle in den Bilderindex aufnimmt. Das war mir bis dahin nicht aufgefallen, obwohl es vermutlich schon eine etwas längere Zeit so ist und auch Sinn ergibt. Es paßt zur Google-Echzeit-Strategie.
Ich freue nich nun schon auf den nächsten SEO-Wettbewerb, dann kann man bestimmte Beobachtungen noch einmal verfizieren und vielleicht weitere interessante Erkenntnisse zur Bildersuche gewinnen. Es muß ja nicht immer der Gewinn des ausgesetzten Preises sein. :-)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}