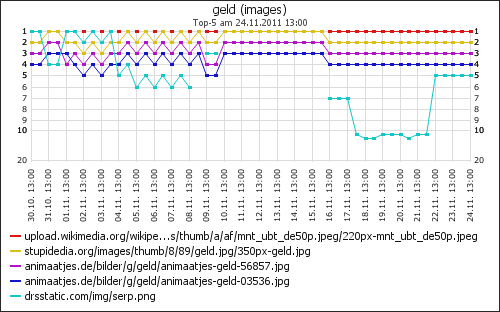
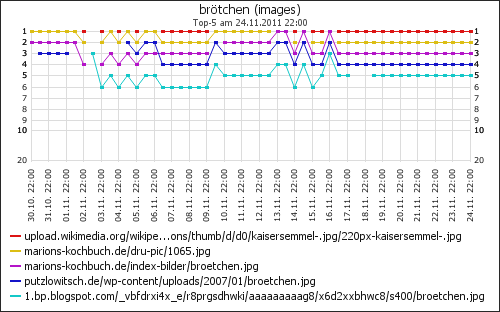
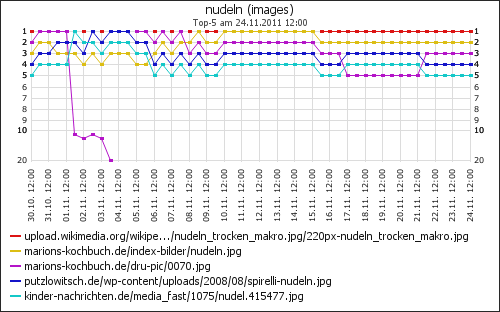
Wo kommen die Besucher her
Ich bin ja ein großer Anhänger der Logdatei-Auswertung für meine Statistik und habe bisher auf andere Tools wie Google-Analytics verzichtet. Alle Informationen konnte ich aus den Server-Logfiles extrahieren, die aufgerufenen Seiten und normalerweise auch, woher der Besucher kam. Dazu überträgt der Webbrowser die entsprechende Information im sogenannten Referrer.
Für Besucher von Google konnte ich auch ermitteln, nach welchen Wörtern sie gesucht hatten. Das zeigt einerseits, was wirklich gesucht wird und wofür meine Seiten gefunden werden. Andererseits gibt es auch immer wieder recht eigenartige Suchanfragen, die Stoff für ein paar lustige Blogartikle liefern.
Google macht dicht
Gestern gab es von Google eine Ankündigung, daß die Suche verstärkt über SSL-Verbindungen (https) abgewickelt werden soll. Bei Twitter und auf Blogs wurde das entsprechend reflektiert, so z.B. bei Prometeo und bei Cashys Blog und natürlich beim GoogleWatchBlog.
Kein Referrer mehr
Im RFC 2616 (HTTP 1.1) findet man unter Punkt 15.1.3 folgendes:
Clients SHOULD NOT include a Referer header field in a (non-secure) HTTP request if the referring page was transferred with a secure protocol.
Mit Clients sind hier die Webbrowser gemeint. Diese sollen also keinen Referer mit schicken, wenn von einer sicheren, verschlüsselten Seite zu einer unsicheren, unverschlüsselten Seite navigiert wird.
Genau das passiert, wenn man auf der verschlüsslten Google-Ergebnisseite auf ein Suchergebnis klickt und z.B. bei mir landet. Meine Seiten sind unverschlüsselt.
Kein Informationen mehr
Was bedeutet das nun für meine Statistik?
Ich weiß bei Besuchern, die von Google kommen, nicht mehr, was sie eigentlich gesucht haben. Ich weiß noch nicht mal, daß sie überhaupt von Google kamen, denn der Referer ist ja leer.
Aber das Problem habe nicht nur ich, sondern auch alle anderen Webstatistik-Tools, selbst Google-Analytics.
Ein Ausweg wäre, man stellt die eigenen Seiten auf https um. Damit bekommen natürlich die Zertifikatsanbieter enormen Zulauf. Bietet Google selbst eigentlich SSL-Zertifikate für Geld an? :-)
Nachtrag:
Was genau im Logfile ankommt oder nicht, hängt auch davon ab, wie der Link zur Zielseite auf der Google-Suchergebnisseite kodiert ist.
Entweder ist das Ziel direkt als URL eingetragen. Dann bleibt der der Referer beim Übergang von der verschlüsselten Suchergebnisseite auf eine unverschlüsselte Zielseite auf der Strecke.
Oder der Klick wird über den Google-URL-Redirector geleitet. Da dieser unverschlüsselt arbeitet, werden nun die Werte im Referer an die Zielseite übertragen, die Google dem Redirector mit auf den Weg gibt. Dabei bleibt z.B. das Abfragefeld q= einfach leer, weil Google das so will und nicht etwa, weil es technisch nicht anders geht.
Das hat also primär nichts mit der Verschlüssselung zu tun. Auch ohne Verschlüsselung der Suchseiten wäre es kein Problem. So etwas Ähnliches gab es übrigens bei der Bildersuche schon mal im Dezember 2007, als Google die Suchparameter im Frameset weggelassen hatte.

")